[Paper Review]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ViT)
Contents
개요
Vision분야에서Transformer를 사용한ViT에 관한 논문에 대한 리뷰를 할 것이다.
Introduction
Self-Attention기반 archtecture인Transformer는NLP에서 중요한 역할을 하고 있다.
- 이때의
주요 접근 방법은아주 큰 text data로 학습시킨 사전 훈련 모델을fine tuning을 하는 것이다.
Transformer의 계산 효율성과 확장성으로 인해 전레없는 크기의 모델을 훈련하는 것이 가능해졌다.
- Model과 dataset이 커져도 성능의 포화는 보이지 않는다.
- 하지만
Vision에서는 CNN 구조가 지배적이었다. NLP의 성공 후, attention을 사용하려는 여러 시도들이 있었지만 특수한 attention pattern의 사용 때문에 효과적으로 사용되진 않았다.- CNN + self-attention의 구조
- CNN을 완전히 대체하는 구조
- 따라서 이런 상황속에서 최소한의 수정으로 image를 직접적으로 Transformer에 넣는 실험을 했다.
Image를 패치로 나누고 이 패치를 linear 한 embedding의 연속으로 나눈 후 이것을 Transformer에 바로 넣는 방식이다.- 그렇게 되면 Image patches는 NLP의 관점으론 token(word)가 되는 것이다.
- 이
ViT를ImageNet과 같은mid-size dataset으로 학습을 했다. 이땐 ResNet보다 몇 퍼센트 낮은 정확도를 보였다.
-
이는 예상된 결과이다. 왜냐하면 기존 CNN은
inductive biases를 가지고 있어적은 양의 데이터로도translation equivariance,locality를 잘하여 일반화 성능이 좋다.-
inductive biases: 모델이 학습된 데이터 외의 데이터에 대해 얼마나 잘 일반화할 수 있는지에 사용하는 가정- 머신러닝의 최종 목표는
generalization, 즉 학습 데이터로 학습시킨 모델이 본 적 없는 데이터에 대해서도 예측(prediction, approximation)을 잘 해내는 것이다. 본 적 없는 상황을 예측하기 위해서는 학습된 가정 이외에 추가적인 가정이 필요한데, 이것이 바로inductive bias이다.
- 머신러닝의 최종 목표는
-
translation equivariance: 입력 데이터가 일정한 변환을 받을 때, 그 변환이 모델의 출력에도 동일하게 반영되는 성질- CNN의 합성곱 층에서는 이미지의 특정 패턴이 위치를 옮겨도 그 패턴을 감지하는 필터의 반응이 동일하게 이동한다. 즉, 입력 이미지의 패턴이 이동하면, 해당 패턴을 인식하는 뉴런의 활성화 위치도 동일하게 이동한다.
- 어떠한 사물이 들어 있는 이미지를 제공해줄 때 사물의 위치가 바뀌면 CNN과 같은 연산의 activation 위치 또한 바뀌게 된다.
-
Locality: 이미지 내의 픽셀들이 인접한 다른 픽셀들과 더 밀접한 관계를 가지는 특성
-
- 그에 반해,
Transformer는inductive biases가 부족하여 데이터가 충분하지 않을 때 일반화가 되지 않는다.
- 그러나 더 큰 데이터 셋으로 훈련을 했을 경우 모델의 성능이 크게 향상이 된다. 따라서 대규모 훈련이 inductive bias를 능가하는 것을 확인을 하였다.
Method
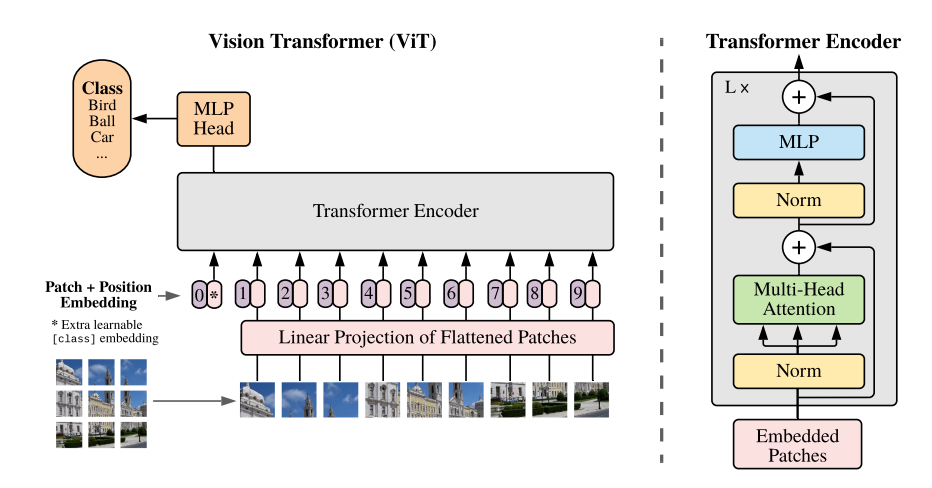
위 사진은ViT의 전체적인 구성에 대한 그림이다. 본 논문에서는 최대한 가능한 원래의Transformer구조를 따를려고 했다.
- 그렇게 되면 확장 가능한
NLP Transformer아키텍처와 그 효율적인 구현을 거의 그대로 사용할 수 있다는 장점이 있기 때문이다.
Vision Transformer (ViT)
ViT의 전체적인 구조를 설명하고 있다. 크게이미지 입력 처리,패치 임베딩,[class] 토큰 추가,position 임베딩,Transformer Encoder 구조순으로 설명할 것이다.
- 먼저
이미지 입력 처리에서 입력 이미지는 $ H * W * C $ (H,W이미지 높이와 너비,C: 채널 수) 크기를 가지지만 1D 시퀀스의 입력을 받는Transformer의 구조에 맞게 변형이 필요하다.
- 따라서 $ H * W * C $ 에서 $ N * (P^2 * C) $ ($N = \frac{H*W}{P^2}$, $P^2$은 각 패치의 크기, C: 채널 수)로 변환을 해야한다. 또한 이 각 패치는 입력에 맞게 linear projection되어 고정된 크기 $D$의 벡터로 매핑이 되어 이 과정을 통해 입력 데이터를 학습 가능하게 변환한다.
Linear projcetion: 입력 벡터에 선형 변환을 적용하여 다른 차원의 벡터로 변환하는 과정.- $y = W * x + b$ 일 때 $y$는 출력 백터로 고정된 크기의 $D$차원의 벡터이고, W는 가중치 행렬로 학습 가능한 행렬이다.
- 이미지 패치가 $16 * 16 * 3$일 때 이 패치를 펼쳐서 $16 * 16 * 3 = 768$크기의 벡터로 나타낼 수 있다
- 이때
Linear projection을 통해 $D = 512$ 크기의 벡터로 변환하려면, $512 * 768$크기의 학습 가능한 가중치 행렬 $W$를 사용해Linear projection을 사용하여 다른 차원의 벡터로 변환하는 것이다.
- 이렇게 projection을 통해 매핑된 벡터들은
patch embedding(패치 임베딩)이라고 불리운다.
- 그 다음
[class] 토큰 추가으로는BERT모델처럼, [class] 토큰을 이미지 패치 임베딩 시퀀스의 맨 앞에 추가한다. (맨 앞 일땐 $z^0_0$)
- 이 시퀀스가
Transformer인코더를 거쳐 나온 [class] 토큰의 최종 출력 $z^0_L$은 이미지 전체를 표현하는 벡터로 사용된다.
- 이 벡터에
Normalization을 적용하면 이미지 표현 $y$를 얻게 된다.
- 즉, 최종 output으로 이 token이 나왔을 때 이미지에 대한 1차원 representation vector로써의 역할을 수행하게 된다.
- 그 다음
position 임베딩은 Transformer에 위치 정보를 함께 주기 위하여 패치 임베딩에 위치 정보를 추가해서 준다.
- 마지막으로
Transformer Encoder 구조는 교차적으로 반복되는Multi-Head Self-Attention와MLP블록으로 구성되어 있다.
- 위 그림처럼 Class token만이
MLP블록을 거친다. - 이때 나온 $y$가 1차원 이미지의 대한 representation vector로써의 역할을 수행하기 때문이다.
$$z_0 = [x_{\text{class}}; x_p^1 E; x_p^2 E; \dots; x_p^N E] + E_{\text{pos}}, \quad E \in \mathbb{R}^{(P^2 \cdot C) \times D}, \quad E_{\text{pos}} \in \mathbb{R}^{(N+1) \times D}$$
- 다음은 본 논문에 나온
(1)에 대한 이해이다.
- 위 식에서 $z_0$은
Transformer의 인코더에 첫 번째 레이어에 입력으로 들어가는 시퀀스이다.
- 첫 번째일 때 $x_\text{class}$는 학습 가능한
[class]토큰이다. 또한 그 뒤의 $x_p^iE$는 $i$번째의 패치 임베딩이다. 이때 $E$는 학습 가능한 linear projection으로 입력 패치를 고정된 크기의 $D$의 벡터로 변환하는 것을 확인 할 수 있다.
- 이때 $x_p^i$는 $ x_p^i \in \mathbb {R}^{N \times (P^2 \cdot C)}$ 으로 $E$와 계산을 하게 되면 $D$차원으로 변경이 되는 것을 확인할 수 있게 된다.
Inductive bias
- 다음으로
ViT는CNN에 비해inductive bias가 작다.CNN에서는locality,translational equivariance을 가지고 있어 공간 정보를 잘 사용할 수 있게 한다.
- 그에 반해,
ViT는MLP만이local,translational equivariance를 가지고 있고self-attention은global한 정보를 가지고 있다.
-
ViT는 이미지를 패치로 나누어positional embedding만을 사용하여 조정하기 때문에locality가 매우 제한적이다. 따라서 모든 spatial 관계는 모델이 학습을 해야한다.Inductive bias: 주어지지 않은 입력의 출력을 예측가능하도록 모델이 가지고 있는 가정들의 집합 즉, 일반화의 성능을 높이기 위해서 만약의 상황에 대한 추가적인 가정이다. 머신러닝은 특정 문제를 풀기 위해 학습 데이터에 대해서 가장 loss가 작은 Hypothesis를 찾는다. 하지만 Hypothesis의 제한이 없다면 overfitting이 일어나므로 제한을 걸어주는데 이 제한이 바로 Inductive bias이다. Inductive bias와 generalization은 서로 Trade-off이다. 그리고 Inductive Bias가 강할수록, 작은 데이터셋에 대해 학습 성능이 더 좋아지는 경향이 있다. Transformer가 부족한 Inductive bias 때문에 성능 향상을 위해 많은 양의 데이터셋이 필요한 대신, robust하게 동작한다. (generalization 성능이 뛰어나서)
Hybrid Architecture
- 기존에는
CNN의feature map에서 입력 시퀀스를 형성할 수 있었지만 본 논문에서 소개하는 구조에서는CNN의feature map에서 추출한 patch에 대해patch embedding을 적용한다.
- 패치가 $1*1$일 땐 단순히 feature map의 공간적 차원을 평탄화하고 Transformer로 투영하여 입력 시퀀스를 얻을 수 있다.
Experiments
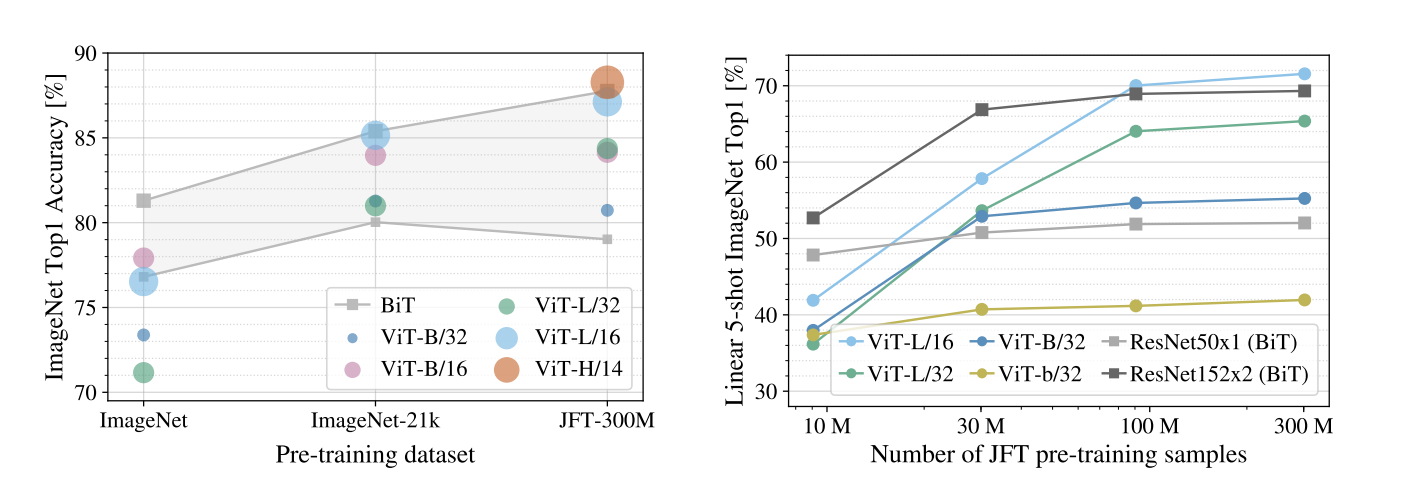

위 그림을 보면 더 큰 데이터로 학습을 했을 때 성능이 훨씬 뛰어난 것으로 확인할 수 있게 된다.
- 그
밑 그림을 보면 왼쪽부터 각각embedding filter,position embedding,attention distance를 보인다.
positional embedding을 보면 각각의 이미지에 대한 위치를 잘 학습한 것을 볼 수 있고attnetion distance그림을 보면 network가 깊어질 수록 image가 통합되는 모습을 확인할 수 있다.
self-attention은 ViT를 통합된 정보를 만들도록 한다.