[Paper Review]Attention Is All You Need
Contents
개요
- 요즘 모든 분야에서 자주 사용되고 있는 아키텍쳐인
Transformer에 대한 논문 리뷰를 해보려고 한다.
Abstract
- 기존의
sequence transduction model(sequence 간 변형이 이루어 지는)은complex recurrent나cnn기반으로 구성되어 있다.
- 그리고 좋은 성능을 내는 것이
attention기반에encoder & decoder기반으로 연결되어 있는 네트워크이다.
- 본 논문에서는 오로지 attention mechanism만 사용하는
Transformer를 제안한다.- 즉,
순환이나cnn의 연산을 사용하지 않는 네트워크이다.
- 즉,
- 이는
훈련시간 절감, 행렬곱을 이용하여 병렬적으로 수행하면서 번역 작업에 우수한 품질을 보여준다.
- English-German 번역 작업에 28.4 BLEU를 달성하였고 다른 task에서도 잘 작동한다.
Introduction
RNN,long-term memory,GRU이 language modeling, machine translation 문제에서 SOTA를 달성하고 있다.
- 많은 연구가 encoder-decoder의와 순환 language model의 성과를 달성하려고 하고 있다.
- 순환 모델의 연산 특성은
training sample내에서 병렬화를 방해하며, 시퀀스 길이가 길어질수록 메모리 제약으로 인해 예제 간 배칭이 제한되므로 병렬화가 중요해집니다.
기존 RNN의 단점
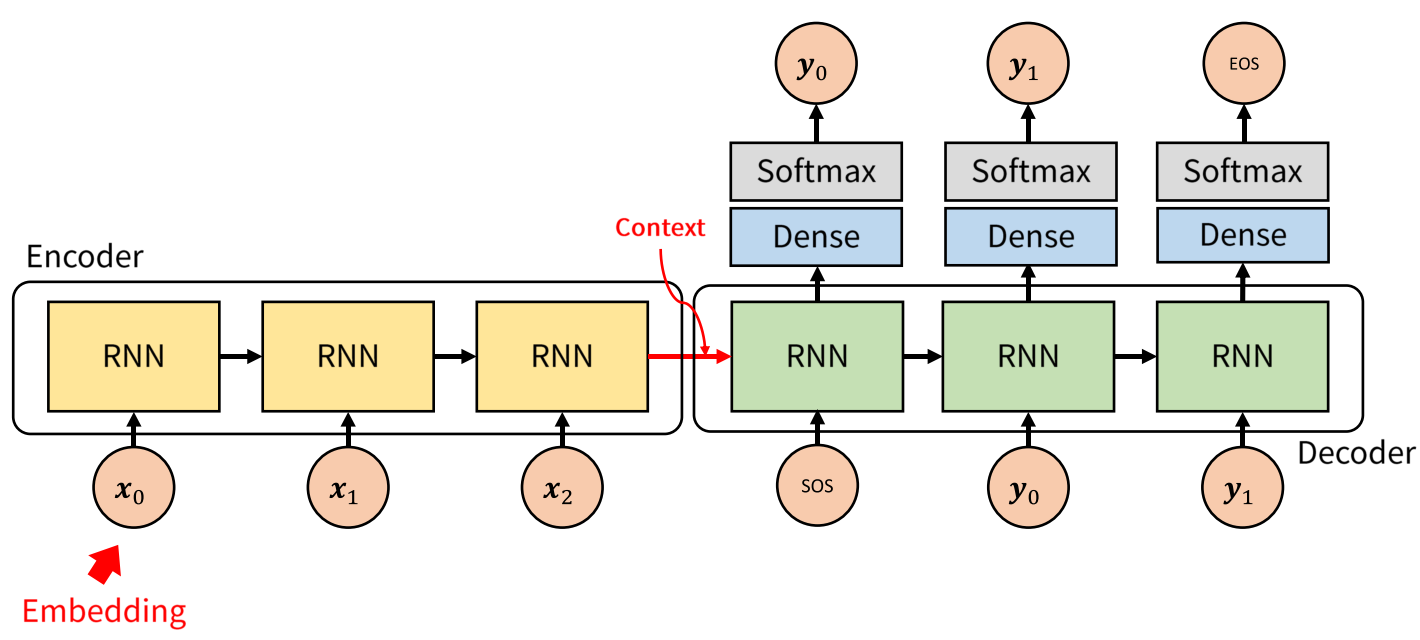
- 따라서 기존의
RNN의 단점에 대해서 간략히 살펴 보겠다.
- 위 그림처럼
sequence에 포함되어 있는 순서 정보를 정렬하고 이것을 차례대로 hidden state의 값을 반복을 통하여 갱신하기 때문에 병렬적으로 수행하기에 어렵다는 사실을 알 수 있게 된다.
- 또한 input 단어가 많아지면 encoder의 마지막 부분의 출력인
context vector를 만들어야 하기 때문에병목의 문제도 있다.
- 다시 논문 내용으로 넘어가면
Factorization trick과 conditional computation의 연구로 인해 이러한 문제점은 상당히 해결되고 있지만 여전히sequential computation은 제약이다.
Attention은input과output의 거리에 관여하지 않고model의 종속성을 허락해준다. 이러한attention mechanism은 주로순환 신경망과 함께 사용이 되어 왔다.
Attention
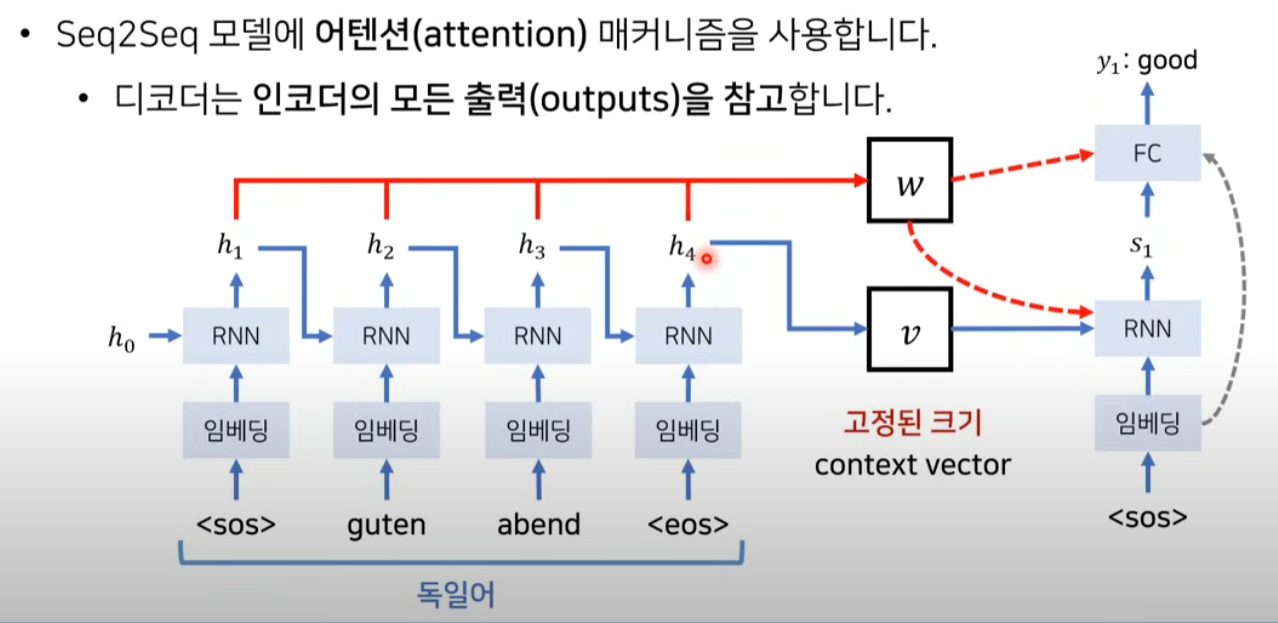
RNN처럼 하나의context vector가 소스 문장의 모든 정보를 가지고 있어야하는 단점을 해결하기 위해 나온 기법이Attention이다.
Attention은 매번 출력 단어를 만들어 낼 때마다 소스 문장의 출력 정보 중에서 어떤 정보가 가장 중요한지가중치를부여해서출력 단어를 보다 효과적으로 생성할 수 있게 한다.
- 간단히 매번 소스 문장에서의 출력 전부를
decoder의 입력으로 받는 방식이다.
- 결론적으로 본 논문에서 제안하는
Transformer는순환을피하고 대신에attention mechanism에 온전히 의존하여input과 output 사이의 ``global dependencies를 이끈다. 이러한 구조는 병렬 처리에 특화되었다.
Background
- 기존 연구들은 CNN을 사용하여 sequenrtial computation을 줄이는데 초점을 맞추었지만 이 방법은 다른 position 사이의 종속성을 배우기 쉽지 않다.
- 하지만
Multi-Head Attention의 방법을 사용하여상수 시간으로 줄였다.
- 또한 기존 순환
end-to-end memory network는 attention mechanism을 사용했다. 하지만 Transformer에서는 RNN이나 CNN을 사용하지 않고input output의representation을 계산하는전체의 self-attention을 사용한다.
- 여기서 나온
Self-Attention이란 input으로 들어오는 각각의 단어가 서로에게 얼만큼의 영향을 미치는지 알려준다.문맥에 대한 정보를 잘 학습하도록 만드는 것이다.
Model Architecture
- 기존 모델들은
encoder-decoder구조를 따르는데 이전 단계에서 생성한 symbol을 활용해서 decoder가 다음번에 나올 output을 만든다.
Transformer또한encoder-decoder의 구조를 띄는데 모델을순환적으로 사용하지 않고attention mechanism만 활용하여 sequence에 대한 정보를 한 번에 입력으로 준다는 것이 특징이다.
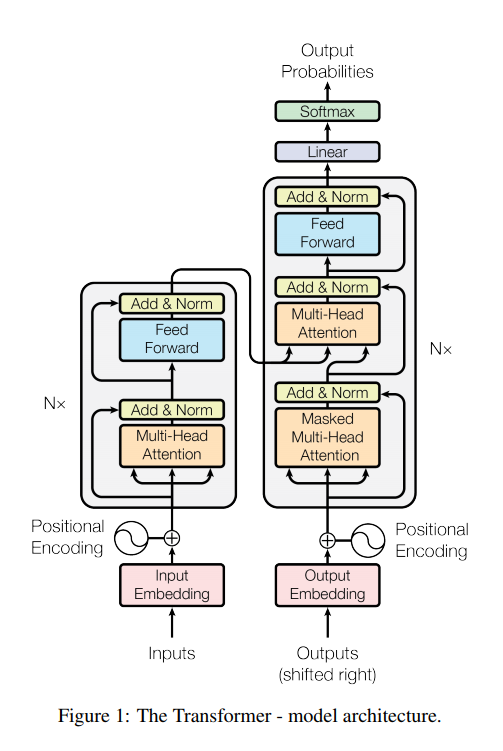
- 위의 그림은
transformer의 전체적인 구조인데 이를 앞으로 하나씩 살펴볼 예정이다.
Encoder and Decoder Stacks
Encoder부분은여러번 stack이 가능한 구조이고 하나의 layer는 크게 두가지의 구조를 지닌다.
- multi-head self attention
- feed-forward network
- 또한 이 두가지의 구조 모두
residual connection을 활용하여Identity mapping을 거치게 한다.
Decoder부분은여러번 stack이 가능한 구조이고 보통 encoder랑 같은 layer의 개수랑 맞춘다.
Decoder third sub-layer에encoder의output값을활용하여multi-head attention을 수행하도록 한다.residual connection을 활용하여 보다 더 쉽게global optima를 찾도록 한다.
- 이전에 등장한 단어들만 참고할 수 있도록 mask를 씌워서
multi-head attention을 사용할 수 있도록 한다.
Attention
Attention Function은쿼리와key-value쌍을 output으로 mapping을 한다.Query, keys, values, output들은 다vector이다.
Query(Q): 물어보는 주체 (어떤 단어가 가장 중요했는지를 key에서 계산하여 결과를 낸다.)
Key(K): 물어보는 대상
- 이는 모두
weighted sum으로 계산이 된다. 그래서Scaled Dot-Product Attention에 대해서 알아볼 것이다.
Scaled Dot-Product Attention
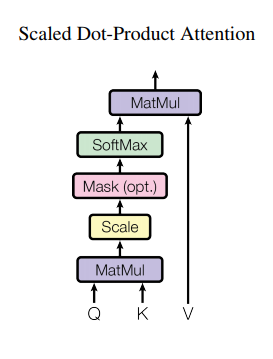
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Attention을 계산하기 위한 방법이다.Input은query와key의dimension $d_k$, value의 dimension $d_v$로 구성이 되어있다.
- 또한
query와key에 대해dot연산을통해 구하고 $\sqrt{d_k}$로 나눈다.- 이때 나누는 이유는 softmax로 들어가는 값을
scaling을 한다.
- 이때 나누는 이유는 softmax로 들어가는 값을
- 필요할 때
mask vector를 사용하고 최종적으로 각각의 key에 대해서 얼마나 중요한지에 대한 값을확률 형태(softmax)로 표현한 뒤에 각각 실제 value랑 곱하여attention value를 구하게 된다.
Multi-Head Attention

$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O $$ $$ \ \text{where } \text{head}_i = \text{Attention}(QW_i^Q,KW_i^K, VW_i^V) $$
- $d_{model}$로 구성된
single attention function을 수행하는 대신에 다른linearly project를 여러번 다르게 학습된 것이 더욱 효과적이라는 것을 알 수 있게 되었다.
- 그리고 이 다른 것
attention function들을 병렬적으로 수행하고 마지막에 합쳐진다.- 이는 서로 다른 위치에서 다양한 표현 하위 공간의 정보를 동시에 주목(attend)할 수 있게 해줍니다.
- 각
head마다 차원을 줄이기 때문에, 전체 계산 비용은 전체 차원에 대한 single-head attention과 비슷한 결과를 보인다.
Applications of Attention in our Model
Attention은 본 논문에서3가지의다른 형태로 나타나게 된다.
첫 번째 방법은Encoder-decoder attention방법이다. 이는각각의 출력 단어가인코더의 출력 정보를 받아와서attention을 수행할 수 있게 만든다. 각각의 출력되고 있는 단어가 src문장에서의 어떤 단어와 연관성이 있는지를 구해주는 것이다.Encoder파트에 있는 attention의 정보가Key,Value가 되고 decoder에 있는 것이Query가 된다.
두 번째 방법은self attention은query,key,value가 다 이전 encoder에서 받아온 결과이다.- 즉, 각각의 단어가 서로에게 얼만큼의 영향을 미치는지 알려준다.
문맥에 대한 정보를 잘 학습하도록 만드는 것이다.Self attention의 관점에서'I am a teacher'가 있을 때I가얼마나 연관성이 있는지 확인하고 싶은 경우I가Query가되고'I am a teacher'의각각 단어가 Key가 된다.
세 번째 방법은Masked decoder self-attention방법이다. 이는mask dot 연산을 하여 출력 단어가 앞쪽에 등장했던 단어만 참고할 수 있도록 만든다.
Position-wise Feed-Forward Networks
- 네트워크에 비선형성과 깊이를 추가하기 위하여
feed forward network를 추가한다.Activation Function: ReLU
Positional Encoding
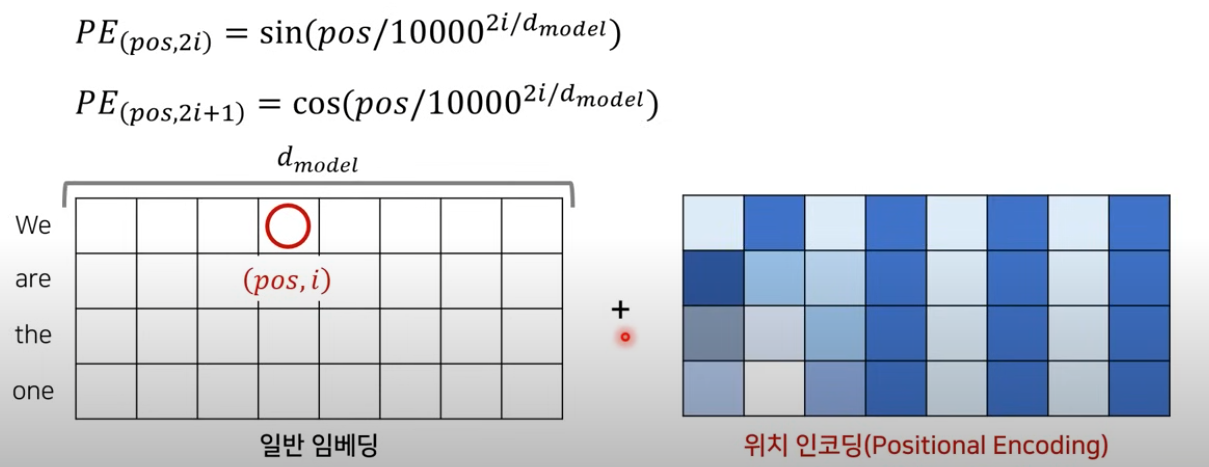
Transformer에서는RNN을 사용하지 않고attension mechanism만 사용하기 때문에 input data에 대한 위치 정보를 포함하고 있는 임베딩을 사용해야 한다.
- 따라서
위 그림처럼 위치 정보를 가진 행렬을 만들고 그것을요소별 덧셈을 하여 계산한다.
Why Self-Attention
- 본 논문은
Self-Attention을 사용했을 때 가지는 세가지 장점에 대해서 설명하고 있다.
첫 번째 장점은 전체적인computational complexity가 다른 순환 모델에 비해서 작다.
두 번째 장점은 병렬적인 처리가 가능하다.
세 번째 장점은long range dependency에 대해서도 처리가 가능하다.
- 또한
interpretable한 모델을 만들 수 있다. 단순히self-attention과softmax를 거친 그 결과값을 보고 모델이 어느 곳을 더 중점을 두는지 확인할 수 있기 때문이다. 한다.