[Paper Review]Rich feature hierarchies for accurate object detection and semantic segmentation
Contents
개요
Object Detection분야에서 널리 사용되는 딥러닝 모델인RCNN에 대한 논문 리뷰를 해보려고 한다.
RCNN은 이미지 내에서 객체를 정확하게 탐지하고 분류하는 문제를 해결하기 위해 개발되었다.
Abstract
- 최근 몇 년간
Object Detection분야가 정체 상태에 있었다. 그동안 가장 성능이 좋은 방법론은low-level image feature와high-level context를 섞는 것이다.
- 본 논문에서는 간단하고 확장 가능한
object-algorithm을 제시한다.- 이는
VOC2012에서SOTA결과 대비 30%나 향상된mAP를 보여준다.
- 이는
- 본 논문에서는 두가지 방법을 사용한다
high-capacity cnn을 하위의region proposal에 적용시킨다.- 이를 통해
RCNN이라고 불린다.
- 이를 통해
- data가 부족할 때,
사전 학습 된 모델을도메인 특화 미세 조정을 하면 성능이 크게 향상된다.
- 따라서
region proposal을CNN과 결합했기 때문에R-CNN(Regions with CNN features)라고 한다.
Introduction
- 지난 10년간
visual recognition task에서의 진전은SIFT와HOG의 사용에 의존되어 왔다.- 둘 다 컴퓨터 비전에서 널리 사용되는 두 가지 이미지 특징 추출 기법이다.
SIFT: 다양한 스케일과 회전에 대해 불변인 키포인트와 불변인 특징을 만드는 기법이다.HOG: 이미지의 지역적인 형태나 외곽선을 표현하는 방법으로, 물체 탐지, 특히 사람 탐지에 사용된다.
- 2010~2012년가지 소폭적인 개선만 이루어 졌다.
AlexNet의 개발로 인하여CNN이 크게 향상이 되었다.
- 그 후
Classification이Object Detection의 결과에 어느정도의 영향을 미치는지에 대해 관건이었다.
- 본 논문은
HOG와 같은 기법들과 비교하여CNN이Object Detection성능을 향상시켰음을 보여준다.
- 이러한 결과를 얻기 위하여
두가지 문제에 집중하였다.Deep network에서의localizing object- 작은 양의
detection data로높은 capacity model훈련하기
Classification과는 달리Object Detection에서는localization이 문제이다.이를 해결하기 위한 방법은 2가지 방법이 있다.Regression problem으로 설정- 실용적으로 좋지 않다. (30%의 결과가 나온다)
Sliding-window detector를 구축- 본 논문의
CNN은 좀 더 깊은(다섯 개의 CNN layer) layer를 구축하였는데 이는높은 spatial resolution을 유지하기 어렵다. - 따라서 이는 객체의 정확한 위치를 찾는데 어려움이 있다는 것이고 이 역시 아직 남아있는 과제임을 나타낸다.
- 본 논문의
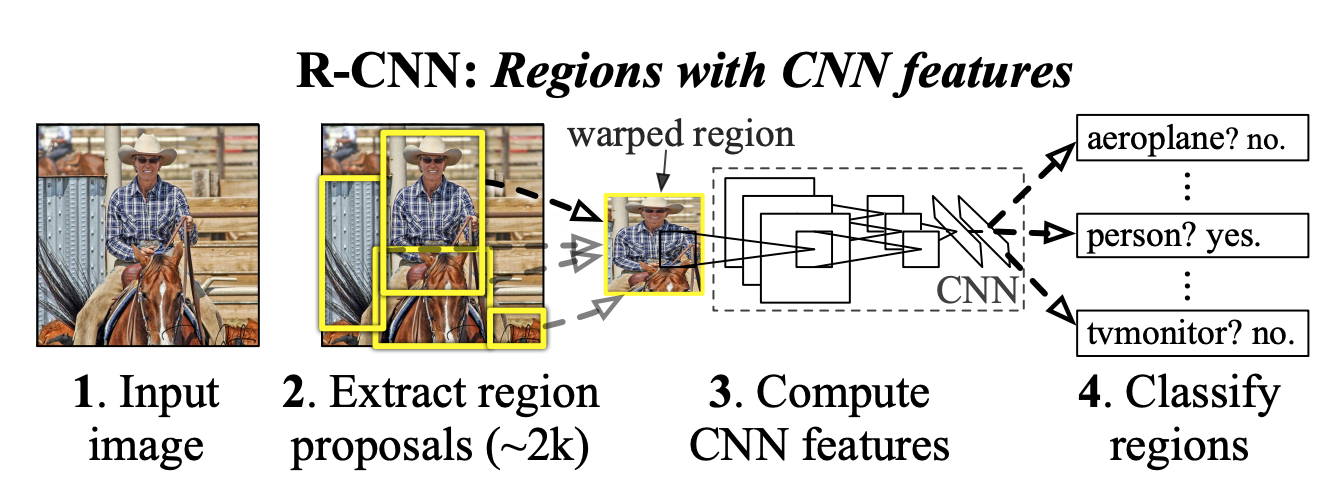
- 본 논문은 첫 번째 문제를
Recognition using region을 통해 해결하려고 한다.
위 그림처럼Region-proposal을 통해2000개의 카테고리를 만들고 이를CNN을 사용해고정적인 길이의 특징 벡터를 추출 한다.
- 이때 입력되는 이미지의 사이즈도 고정되어야 하기 때문에
아핀 변환등으로 이미지를 추출한 후 입력으로 사용한다. 그 후 이를 선형 SVM으로 분류한다.
- 이는 영역의 크기에 상관없이 동일한 크기로 변환이 된다. 본 논문에서는 이를
Region-proposal과CNN을 같이 사용하므로R-CNN이라고 한다.
- 본 논문은 두 번째의 문제를 사전 학습 미세조정에 따른 비지도 사전 훈련을 허용하여 해결했다.
ILSVRC인 임의의 큰 데이터로 지도 학습을 한 모델에PASCAL의작은 데이터를 domain 특화 미세 조정을 하는 패러다임을 제시한다. 이를 통해 결과가33%가 올랐다.
Object Detection with R-CNN
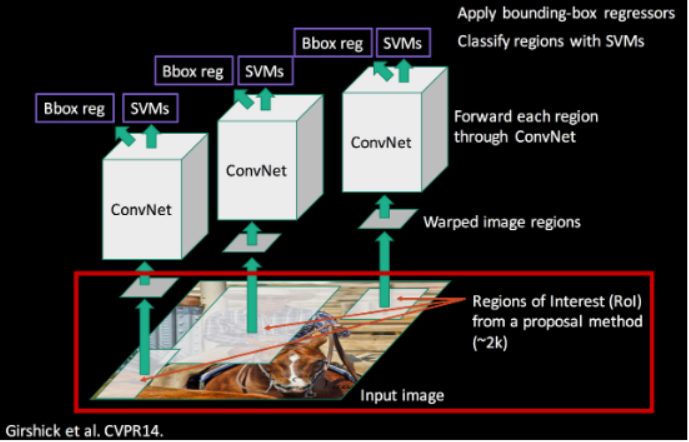
- 크게
3가지 모듈을 포함하고 있다.- Category-independent
region proposal - Large
Convolutional neural network - Class specific linear SVM
- Category-independent
-
본 논문에서는
Region-proposal을 생성하기 위해Selective Search방법을 이용한다.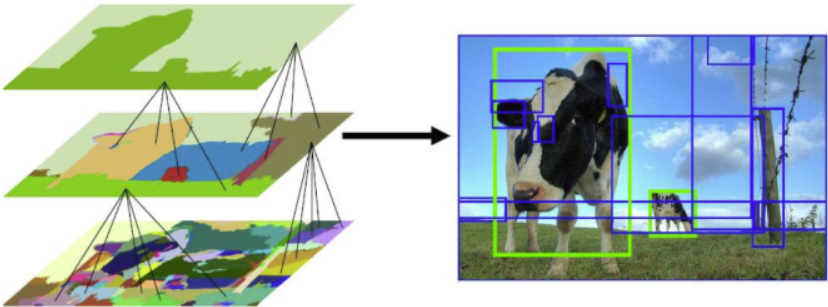
Selective Search란 색상, 질감, 영역크기 등을 이용해non-objective segmentation을 수행한다. 이 작업을 통해좌측 제일 하단 그림과 같이 많은 small segmented areas들을 얻을 수 있다.Bottom-up방식으로small segemented areas들을 합쳐서더 큰 segemented areas들을 만든다.두 번째의 작업을 반복하여 최종적으로2000개의region proposal을 생성한다.
-
또한 본 논문에서는 AlexNet의 모델을 사용하여 $227 * 227$의 고정적 크기인 이미지를 받게 한다.
- 따라서 임의의 다양한 크기를 가진 영역들을 고정된 크기로 바꾸는 작업인
warping의 과정을 거친다.
- 2000장의
region-proposal이selective-search에 의해 나오면ground-truth와IoU를 비교하여0.5 보다 큰 경우를positive로 구분하고 그 외를negative로 구분한다.- 또한
positive랑negative가 겹치는 객체를 정확히 탐지하기 위하여IoU overlap threshold를 사용하여IoU 임계치를 주어 객체 탐지 성능을 높인다.
- 또한
- 또한 기존의
pre-trained된AlexNet의 마지막 layer를 수정해서기존 ImageNet인1000-way classification이 아닌 $N+1$way classification을Stochastic Gradient Descent (SGD)를 통해 수행하게 된다.- $N$은
object calss의 수 - $1$은 배경인지 판단하기 위한
backgroud이다.
- $N$은
- 이때 수정한
layer는R-CNN모델 사용 시 사용하지 않는다. 왜냐하면 이layer는fine-tuning을 위해 사용한 것이고 원래R-CNN에서의CNN의 목표는4096 dimensional feature vector를 추출하는 것 이기 때문이다.
- 이렇게 추출된
feature vector를 이용해linear SVMs를 학습한다. (SVM은 객체의 종류만큼 필요하다.)- 단순히
N-way softmax layer를 통해 분류를 진행하지 않고SVM을 통해 분류하는 것이 성능이 더 좋게 나온다고 말한다.
- 단순히
- 이때
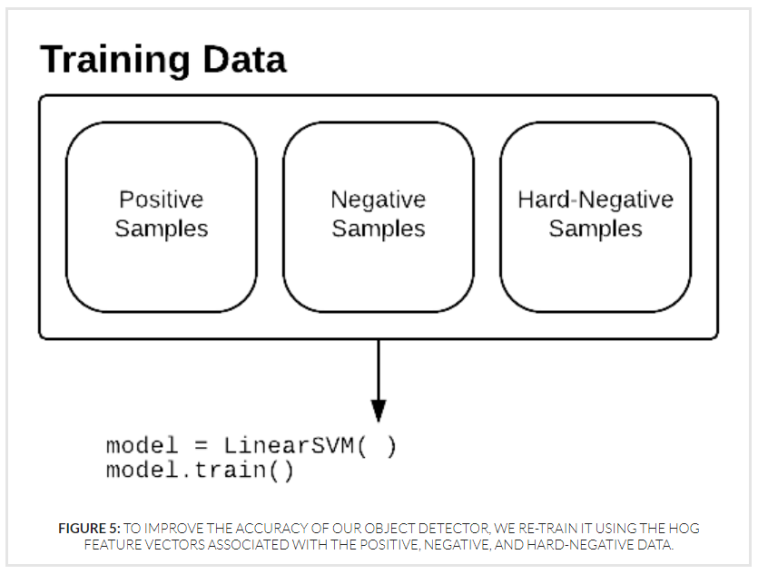
SVM을 이용하여 분류할 때 학습이 한 차례 끝난 후hard negative mining기법을 적용한다.
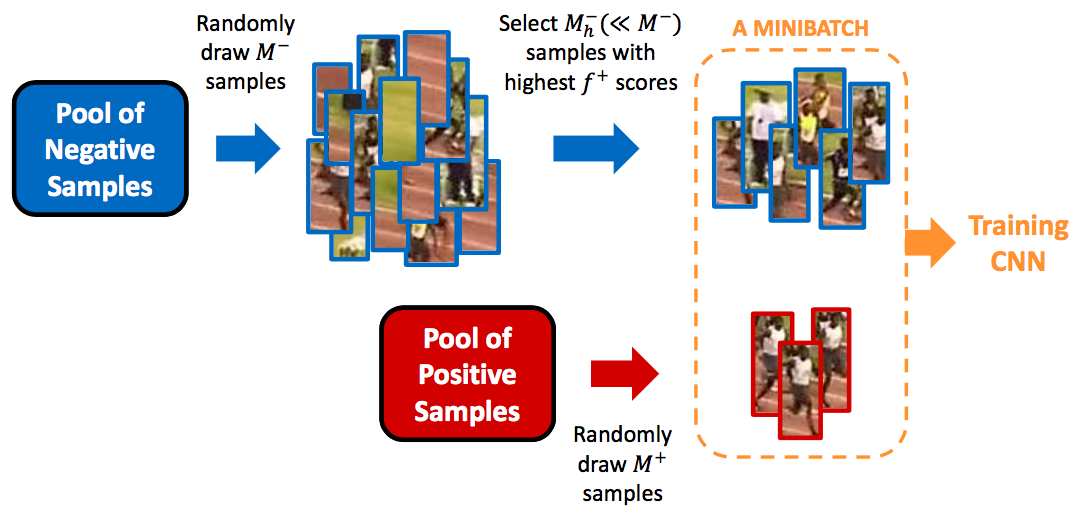
Hard negative mining이란 모델이 예측에 실패하는어려운(hard) sample들을 모으는 기법으로,hard negative mining을 통해 수집된 데이터를 활용하여 모델을 보다 robust 학습시키는 것이 가능해진다.
- 예를 들어 이미지에서
사람의 안면의 위치를 탐지하는 모델을 학습시킨다고 할 때,사람의 안면은positive sample이며, 그외의배경은negative sample이다. 이 때 모델이 배경이라고 예측했으며, 실제로 배경인 bounding box는True Negative에 해당하는 sample이다. 반면에 모델이 안면이라고 예측했지만, 실제로 배경인 경우는False Positive sample에 해당한다.
- 모델은 주로
False Positive라고 예측하는 오류를 주로 범한다. 이는Object Detection시, 객체의 위치에 해당하는positive sample보다 배경에 해당하는negative sample이 **훨씬 많은 클래스 불균형(class imbalance)**으로 인해 발생한다.- 탐지하려는 객체보다 배경이 더 많기 때문이다.
- 따라서
위 [그림 1]처럼 모델이 잘못 판단한False Positive sample을 학습 과정에서 추가하여 재학습하면 모델은 보다 robust해지며,False Positive라고 판단하는 오류가 줄어든다.