[Paper Review]Multimodal Machine Learning: A Survey and Taxonomy
개요
Multi-Modal Learning에 관련한 서베이 논문을 리뷰해보려고 한다.
Introduction
-
세상을 둘러싼 환경은 여러
modality를 포함하고 있다. 사람들은 이러한modality를sensory modality(vision or touch)와 연결을 짓는다. -
본 논문은
natural language,visual,vocal signal에 관해서 중점을 두어 설명을 한다. -
Multi modal을AI에 사용하기 위해서는multimodal message에 대해여러 정보(multiple modalities)를 연결시킬줄 알아야 한다. -
또한 여러 데이터 간
데이터의 이질성으로 인하여Multimodal machine learning에서는 여러 해결해야할 문제가 있는데 본 논문에서는 5개를 제시한다. -
첫 번째는
Representation이다. 이는 multimodal data를 어떻게 잘 요약하고 표현을 할 지에 대한 문제이다. -
두 번째는
Translation이다. 이는 하나의modality에서 다른 하나의modality로 어떻게 mapping(translate)을 할 지에 대한 문제이다.
- 이미지에 대한 올바른 방식의 해석이 있어도 단 하나의 완벽한 해석은 존재하지 않는다.
- 세 번째는
Alignment이다. 이는 여러개의modality로부터 요소 사이의 관계들을 정렬하여 식별하는 것이다.
- 서로 다른
modality간의 유사성을 측정하고, 가능한 장거리 의존성 및 모호성을 처리해야 한다.
- 네 번째는
Fusion이다. 여러modality의 추론 결과를 합치는 것이다.
- 다른
modality로부터 오는 정보들은 다양한 예측 결과를 가져올 수 있다.
- 다섯 번째는
Co-learning이다.Modality간에knowledge를 전달하는 것이다.
- 이것은 한
modality의 data가 부족할 때 유용하다.
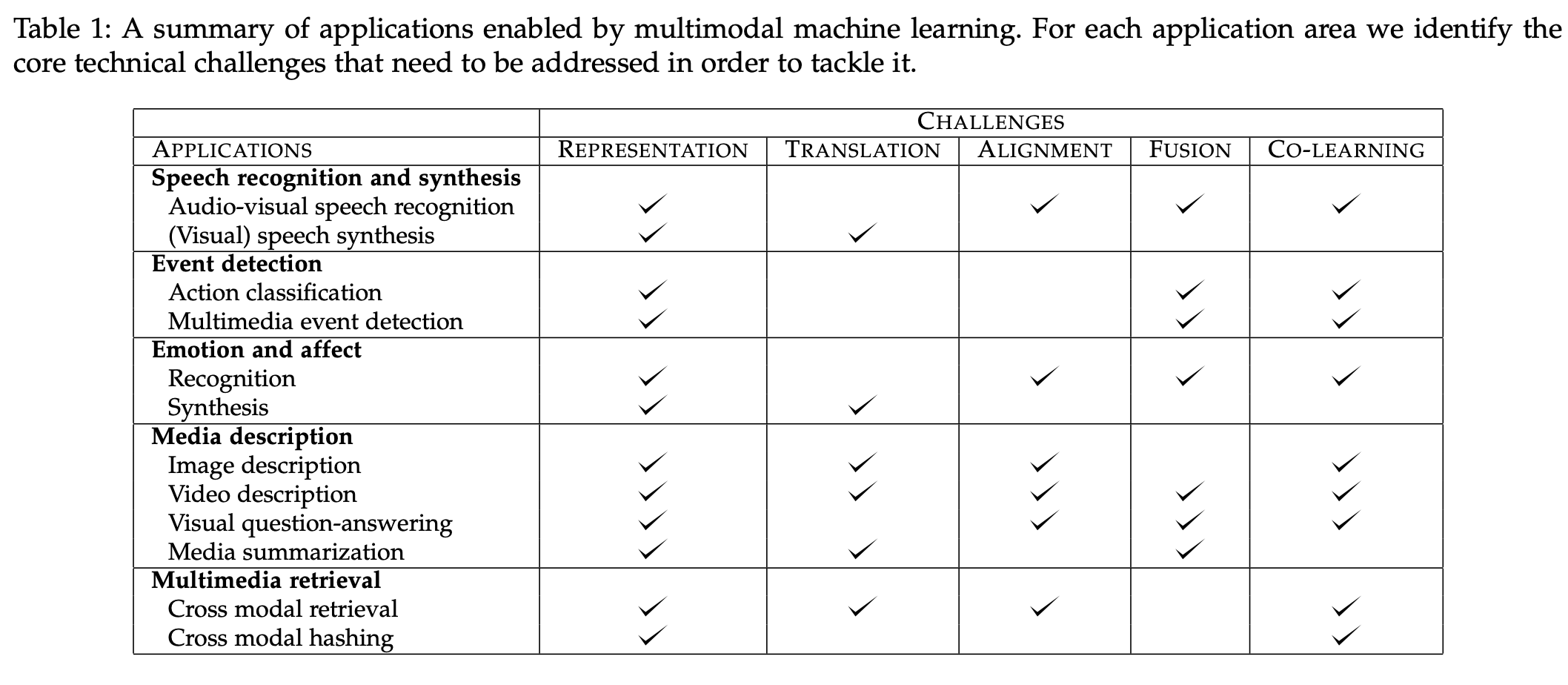
-
위 표는multi-modal을 적용하는application에서 위에 설명한5가지의 challenge의 포함 여부를 나타낸 것이다. -
위 표를 확인하며multi-modal로 활용할 수 있는task가무엇인지도 함께 확인하면 될 것 같다.
Representation
-
이젠 5가지의
challenge에 대해서 설명할 것이다. 먼저 첫 번째로 설명하는Multimodal Representation에 대한 설명이다. -
여러
modality를representing하는 것은 다양한 어려움이 존재한다.
- 이질성인 데이터에서 어떻게 섞을 것인지
- 다른 종류의 noise를 어떻게 처리할 것인지
- missing data를 어떻게 처리할 것인지
-
좋은
representation하는 방법은model의 성능을 중요하다. (최근speech recognition,visual object detection등의 성능 향상 사례가 있다.) -
또한 좋은
representation을 위한 몇 가지 속성으로부드러움(smoothness),시간적 및 공간적 일관성(temporal and spatial coherence),희소성(sparsity),자연스러운 클러스터링(natural clustering)등이 있다. -
Multi modal representation을 위한 여러 속성들이 있다. 그것은표현 공간에서의 유사성이다. 이는 해당 개념들의 유사성을 반영해야 하며, 일부 modality가 없어도 쉽게 표현을 얻을 수 있어야 하고, 관찰된 modality를 바탕으로 누락된 모달리티를 채울 수 있어야 합니다. -
이전까지 단일
modality에 대한 연구는 광범위 하게 연구되어 왔다. 이미지에 관련한data는SIFT기법에서CNN기법으로 연구되어 왔고audio domain은 음향적 특징들이deep neural network에서rnn으로 연구되어 왔다. -
이런 와중
multi-modal에선 단일 modality에 대한 연구들을 단순히 concat하는 방법만 사용하고 있다. 이런 방법론들이 변화되고 있다.
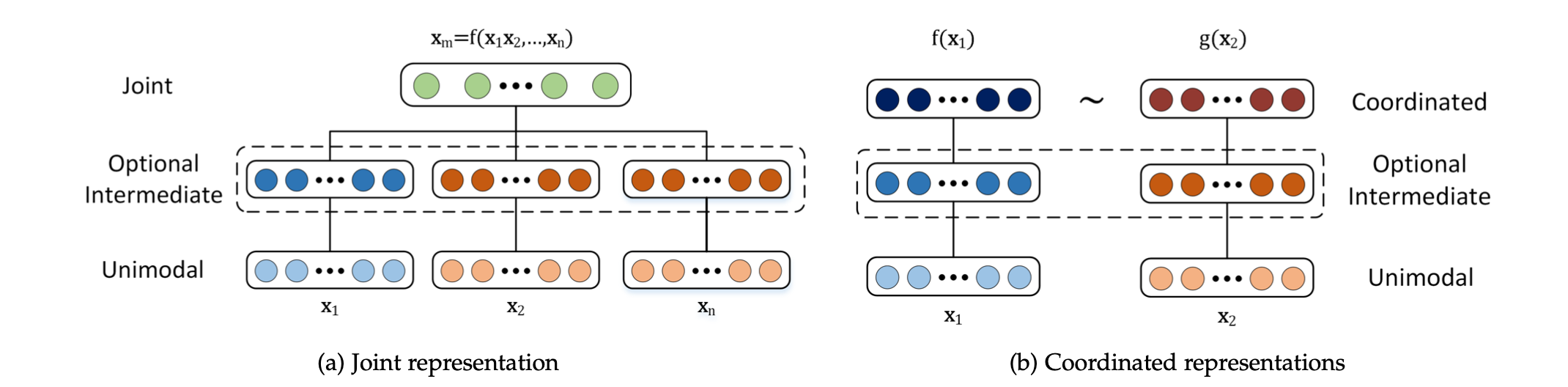
-
따라서, 본 논문에선
joint와coordinated라는두 가지의 representation 방법을 소개한다. -
joint는 각각의modality를 같은representation space에 결합하는 방식이다. 이는 아래와 같은 수식으로 표현할 수 있다. ($x_1, x_n$등은 각각 modality이다.)
$$ x_m = f(x_1,…,x_n)$$
coordinated는 각각의modality를 각각 분리해서 처리하지만similarity 규정을 사용해coordinated space에 가져온다. 이는 아래와 같은 수식으로 표현할 수 있다.
$$f(x_1) ~ g(x_2)$$
Joint Representation
-
Joint Representation은독립적인 modality 특징들을concatenation을 한다고 생각하면 된다. -
앞으로는
data의 representation 방법중 가장 유명한 방법인Neural network에서Joint Representation을 하는 방법에 대해서 설명할 것이다. -
Neuraul network을 사용해multi modal representation을 구축하기 위해 각modality는 여러 개의 개별 신경 계층으로 시작하고, 이후 이modality들을joint space에 투영하는hidden layer가 따른다. -
이렇게
joint된representation들은 hidden layer를 거치거나 예측에 직접적으로 사용을 한다. -
이런
neural network에서 훈련을 할 때, 많은 label data가 필요하게 된다. 따라서unsupervised data에서autoencoder를 사용해 이러한 표현을pre-training하는 것이 일반적이다.
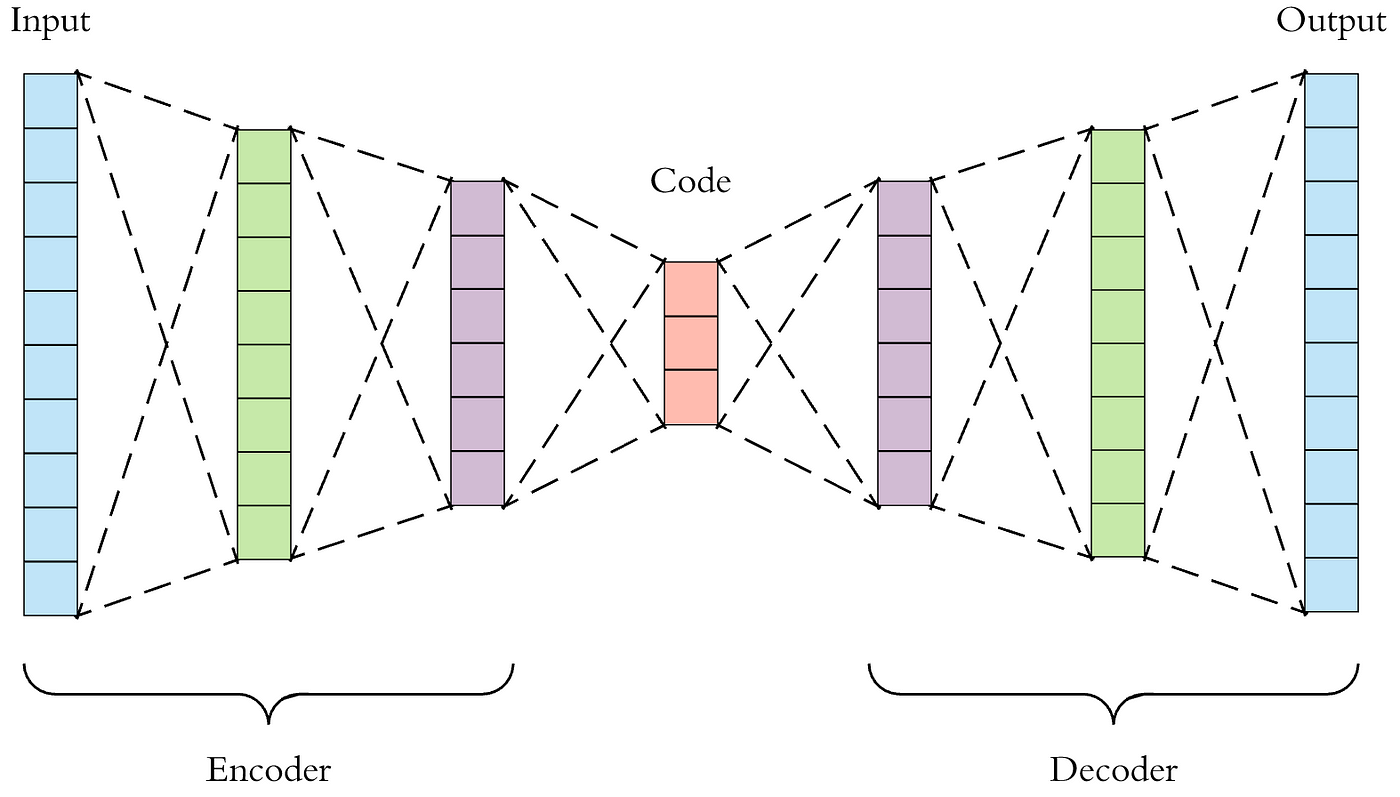
- 하나의 예시로
denoising하는 여러개 autoencoder를 stack한 후다른 autoencoder layer를 사용하여 fuse하게 된다.
- 이런
autoencoder를multi-modal에서 representation을 잘 학습하기 위하여reconstruction loss를 사용하고 그representation을 사용하여object label을 예측할 수도 있게 한다.
-
또 다른 방법으로는Probabilistic graphical model이 있다. 이는latent random variable에서representation을 재구성하는 방법이다. -
Graphical model에서 가장 유명한 방법은 restricted Boltzmann machine(RBM)을 쌓아 올린 deep Boltzmann machine(DBM)이다. 이는 앞서 설명한autoencoder와 같이unsupervised learning이 가능하다. -
이 방법은
neural network로도 변환이 가능하다. 이 방법의 장점은 생성적 특성이다. 따라서 missing data가 있어도 하나의 modality가 있어서 다른 modality의 특성을 생성해낼 수 있다. -
하지만 높은 computational cost 때문에 훈련이 어렵고 적절한
variational training method를 사용해야한다는 문제점이 있다. -
다음으론 고정된 길이가 아닌 연속적인 성격을 지닌 data(audio, video, sentence 등)을 model이
represent하는 방법에 대해서 설명할 것이다. -
RNN과LSTM은sequence model에서 훌륭한 성과를 내고있다.RNN의hiddein state는 data의representation이라고 볼 수 있다. 왜냐하면RNN의 encoder에서 나온hidden state의 조합으로 decoder가 재조합 하는 것 이기 때문이다.
Coordinated Representation
-
각각의
modality에서representation을 얻은 다음에constraint를 통하여 조정을 하게 하는 것이coordinated representation방법이다. -
비슷한 모델은
coordinated space에서 가까운 거리를 가지는 경향이 있다. 예를 들어 dog라는 단어와 dog를 나타내는 이미지 간에 distance가 dog와 car를 나타내는 이미지의 distance보다 짧은 것을 확인했다. -
따라서 이와 비슷한 모델로
WSABIE(web scale annotation by image embedding)의 설명이 나온다. 이 모델은 이미지와 그 주석들을 위한coordinated공간을 구축했다.
- 이미지와 텍스트 특징 간에 간단한 선형 맵을 구성하여 해당하는 주석과 이미지 표현 사이의 내적(inner product)이 더 크고
- 일치하지 않는 주석과 이미지 표현 사이의 내적은 상대적으로 작게 하였다.
- 최근에는
WSABIE와 유사하지만 더 복잡한 이미지와 embedding을 사용할 수 있는neural networkDeViSE(A deep visual-semantic embedding)을 소개한다. 이 모델에서 내적 연산, ranking loss를 사용하였다.
- 이러한 모델은
end-to-end방식으로 학습을 할 수 있는 장점이 있다.
Structured coordinated space는representation의 유사성을 강제하는 것 뿐 아니라modality의 추가적인constraint를 더한다.
- 적용 분야에 따라 constraint가 달라진다.
-
Cross-modal hashing에서 자주 쓰인다.Cross modal hasing은 높은 차원의 data를 압축하여 비슷한 객체에 대해 유사한 이진 코드를 갖는 소형 이진 코드로 변환하는 것이다. -
이는
Cross-modal 검색을 위해 이런 해시 코드들이 만들어 진다. -
이때 hashing은 결과로 얻어진
multi modal 공간에 대해 다음과 같은 특정 제약을 강제한다. 또한 이런 제약은hash function으로data representation을 표현하는 방법을 훈련하면서 세 가지를 충족하려고 한다.
- N차원 해밍 공간이어여 하며, 제어 가능한 이진 표현이어야 한다.
- 다른
modality로부터같은 object를 가지면유사한 hash code를 가져야한다. - Space는
similarity-preserving이어야 한다.
-
앞선 방법으로 문장 description과 해당 이미지 간의 공통 binary space을 학습하는 방법을 딥러닝에 적용하는 예시가 있다.
-
또한
Structured coordinated space의 다른 예로이미지와언어의순서 임베딩에서 찾을 수 있다. 언어와 이미지 표현의 부분 순서를 캡처하여 공간에 계층 구조를 강제하는 것이다.
- 예를 들어, “여자가 개를 산책시키고 있는 이미지” → “여자가 개를 산책시키고 있다"라는 텍스트 → “여자가 산책 중이다"라는 텍스트로 이어지는 순서를 강제하게 된다.
Translation
- continue