[Paper Review]Fully Convolutional Networks for Semantic Segmentation(FCN) & Implement
개요
- Semantic Segmentation 문제를 해결하기 위해 제안된 딥러닝 모델인 Fully Convolutional Networks(이하 FCN) 논문 리뷰를 해보려고 한다.
Abstract
-
FCN은 convolutional network 자체로
end-to-end 학습,pixels-to-pixels을 훈련을 하고 semantic segmentation에서 state-of-the-art(이하 SOTA)를 달성했다. -
이때 나오는
end-to-end 학습이란 독립적인 것이 아니라 하나의 모델에서 작업이 다 끝나고, 모델의 모든 filter들이 학습이 가능한 학습을 하는 학습 방법이라고 생각하면 된다.
[그림 1] end-to-end 학습 end-to-end 학습이 아닌 모델인 pattern recognition모델은 사람들이 직접 filter를 설계하여 classifier만 학습을 하는 방법이다.
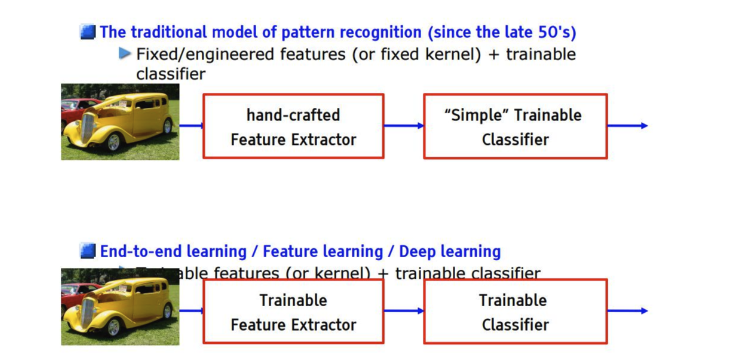
- 본 논문의 핵심 아이디어는 임의의 크기인 input과 input과 같은 크기의 output을 생성하는
fully convolutionalnetwork를 구축하는 것이다.
- 또한 기존의 classification networks(AlexNet, VGG net, GoogLeNet)을 통해 transfer learning을 통한 fine-tuning을 진행하였다.
- 마지막으로 모델의 deep layer에서 얻은 의미(Semantic) 정보와 shallow layer에서 얻은 외관(Appearance)정보를 섞는
skip architecture를 정의하였다.
[그림 2] CNN layers

- Semantic information
deep, coarse(굵다) layer
- CNN에서 제일 deep한 위치에 있는 layer들이 객체의 외관은 파악하기 힘든 반면에 feature들이 활성화가 된 부분을 보면 의미가 있는 정보를 나타낸다.
- Appearance information
shallow, fine layer
- CNN의 첫 번째 layer에 있는 filter들은 보통 edge feature들을 추출하기 때문에 윤곽과 관련된 feature들을 추출한다.
Introduction
- Convolutional networks의 등장으로 인해 classification, local task(object detection, key-point등)와 같은 분야에서 엄청난 발전을 이룰 수 있었다.
- 이러한 Convolutional networks의 다음 단계는 segmentation을 위한 모든 pixel에 대한 예측이다.
- 또한 기존의 방법들 (
patchwise training,pre-post processing)등의 수고로움을 해결할 수 있다고 나와있다.
- 이때 설명하는
patchwise training이란 FCN이 나오기 전 segmentation 학습 방법론 이다.
[그림 3] Patchwise training Patchwise learning방식- 특정 크기의 patch를 설정 및 CNN input
- 이때의 input -> CNN에 의해 classification이 된다.
- 이때 특정 class로 분류가 되었다면, 해당 patch 중앙에 위치한 pixel을 분류된 class로 분류한다.
- 이 과정을 슬라이딩 윈도우 방식으로 모든 픽셀을 반복한다.
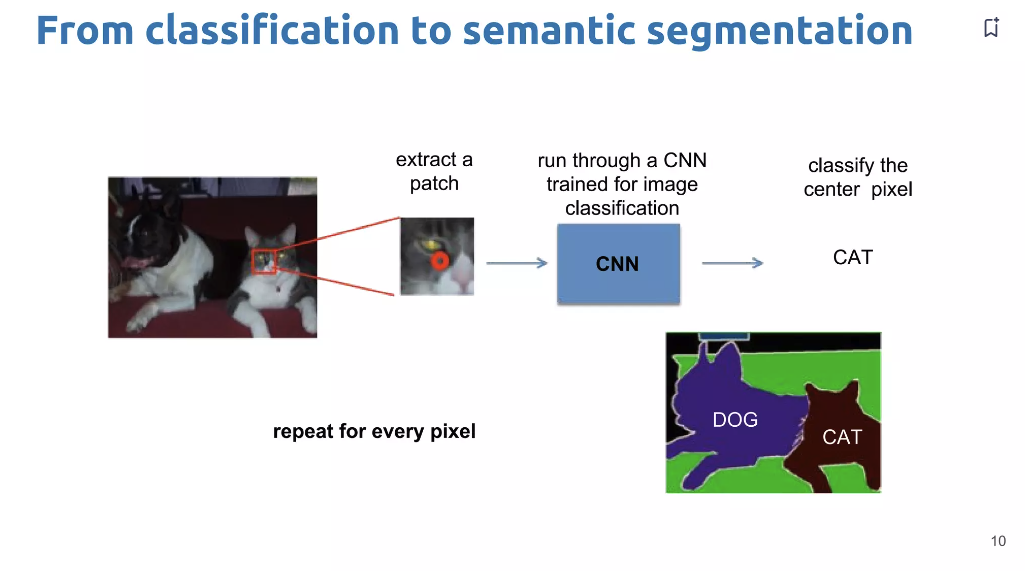
- 따라서
Patchwise learning의 방법에는 여러 단점이 생기게 된다.
- 많은 계산량
- patch끼리 겹칠 때의 중복 계산의 우려, patch의 크기를 크게할 때 분류가 애매한 상황
- patch 크기를 줄여주면 low resolution(해상도가 낮음)의 문제
- 마지막으로 FCN이 등장하기 전
semantic한 정보와location한 정보를 어떻게 잘 조합할 지 몰랐다. 이를 해결하기 위해서skip architecture가 나오게 된다.
Fully convolutional networks
- 이제까진 기존 CNN에 대한 설명과 FCN이 나오기전의 모델들의 단점들을 살펴보며 FCN 모델의 우수성을 추상적으로 설명했다. 이젠 FCN의 알고리즘을 구체적으로 설명 해보려고 한다.
Adapting classifiers for dense prediction
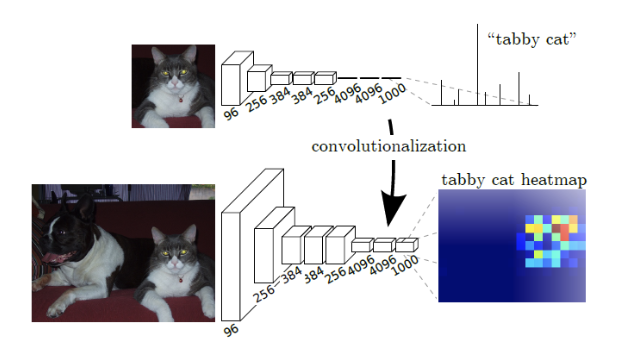
- 전형적인 분류 net(LeNet, AlexNet …)은 FC층 때문에 고정적인 input size와 non-spatial output을 가진다.
- 입력 이미지의 크기에 비례하여 FC층에 들어가기 위해 flatten되는 neuron의 수가 비례하기 때문에 input size가 고정적이다.
- 이때 flatten 되기 때문에 이미지의 공간적 정보의 손실이 있게 된다.
- 따라서 이러한 linear한 FC층을 [그림 1]처럼 Fully Convolutional한 구조로 변경을 하였다.
- 이로써 모든 layer에 Conv를 적용하여 ground truth를 각 layer의 출력으로부터 얻을 수 있어 forward와 backward가 계산 효율성에서 장점을 얻는다. 또한 단점이었던 공간 정보의 손실이 없어지는 것도 해결하였다.
- convolutionalization된 층의 resulting map에 해당되는 특정 위치가 특정 patch 상의 CNN 결과랑 같게 된다.
- 지금까진 FCN구조의 encoder 부분을 설명한 것과 같다. 다음으론 output map(coarse output)으로 부터 dense prediction을 하는 방법을 알아 볼 것 이다.
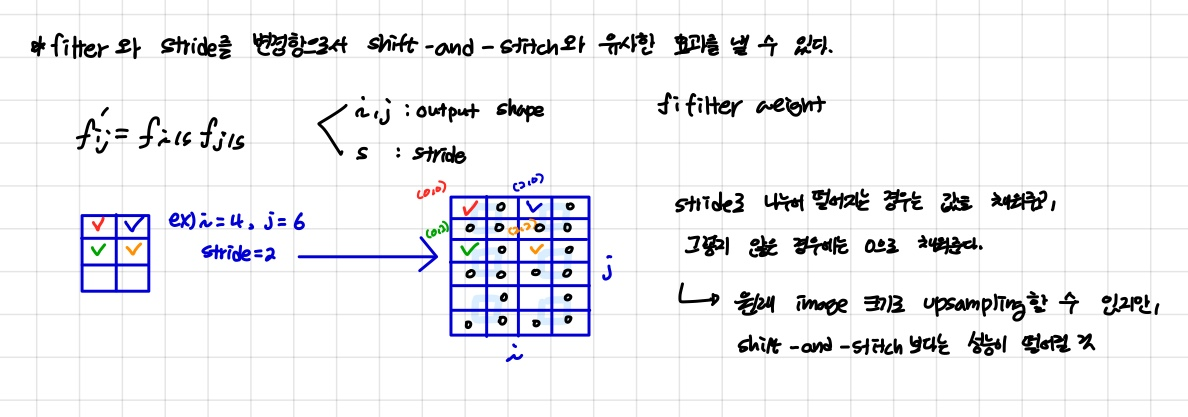
Shift-and-stitch is filter rarefaction
- dense prediction을 하기 위해 output map을 upscaling을 해야 한다. upscaling을 하기 위한 방법으로 본문에선
shift-and-stitch방법을 고려했다고 나타난다.
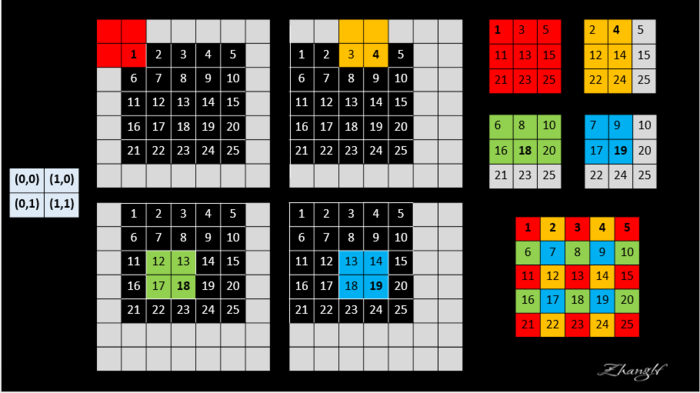
- 그림을 토대로 max pooling을 하고 위치 정보를 저장하여 원래의 이미지 크기로 upscaling이 가능하다. 하지만 계산 비용이 큰 단점이 있게 된다.
- 또한 shift-and-stitch와 유사한 효과를 기대할 수 있는 trick을 고려했다고 한다. 이 방법은 upscaling시 기존 픽셀이 s로 나누어 떨어지면 넓어진 영역의 픽셀로 들어가고 그렇지 않으면 0으로 채워지는 방식으로 사용을 한다.
 출처: https://jlog1016.tistory.com/84
출처: https://jlog1016.tistory.com/84
- 지금까지 upscaling을 하기 위한 2가지 방법을 설명했다. 하지만 논문에서는
skip connection을 사용한 upscaling이 더욱 효과적이기 때문에 결론적으로 이 두 방법을 사용하지 않았다.
Upsampling is backwards strided convolution
- coarse한 출력을 dense한 픽셀로 바꾸는 방법은 크게 두 가지가 있다.
Interpolation기법Deconvolution기법
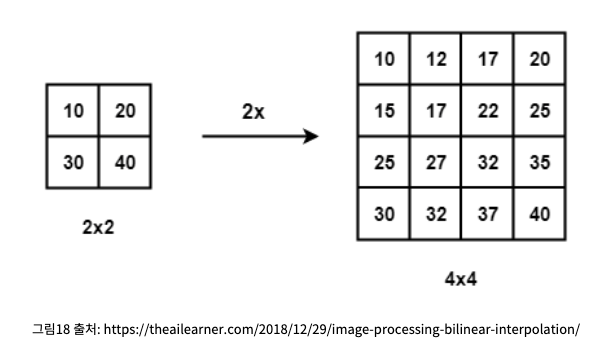
- 먼저
Interpolation을 살펴본다면 아래 그림과 같이interpolation(보간법)을 이용하여 4개의 입력이 있다면 상대적인 위치에 의존하는 linear map을 통해 계산이 수행이 되어 upsampling을 할 수 있게 된다.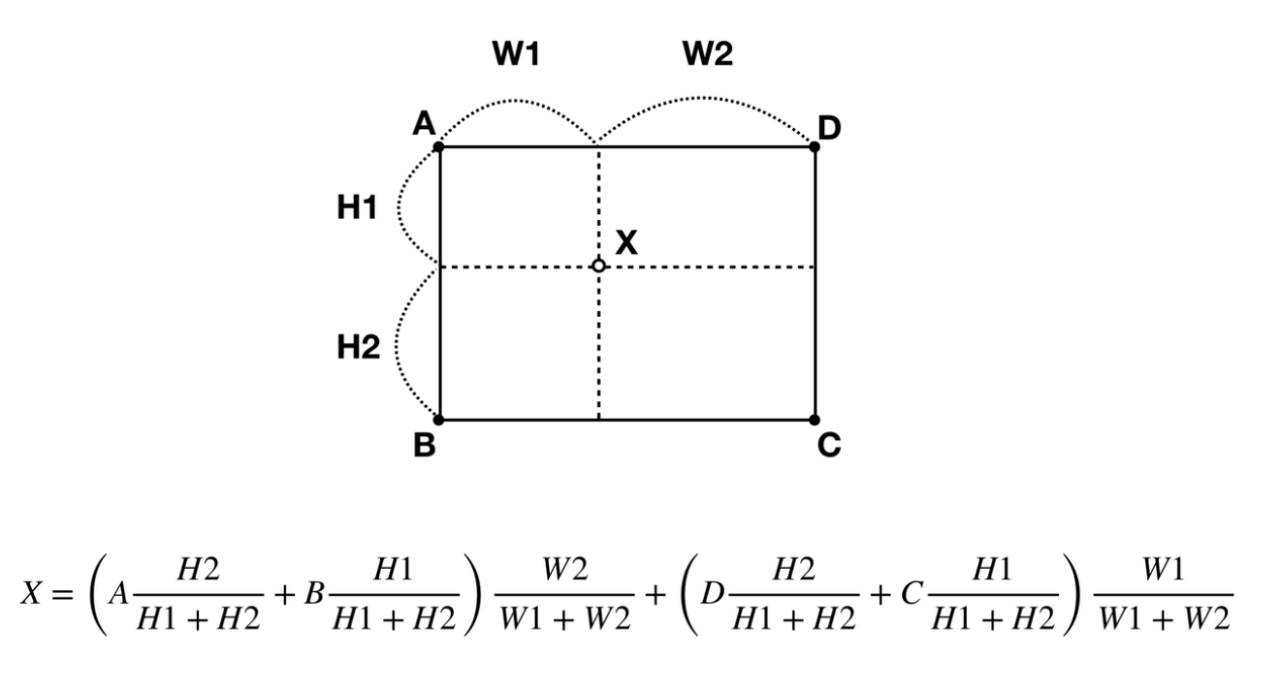
- 다음으로
Deconvolution기법을 살펴본다면 factor f로 upsampling하는 것은 input stride가 1/f인 convolution인 의미이다. (f로 stride를 진행하면 작아지므로 같은 크기로 커지게 하려면 f의 반대인 1/f가 되어야 한다.)
- 이렇게 된다면 이 필터도 downsampling하는 필터와 마찬가지로 미분 가능하기 때문에 학습이 가능하고(chain-rule) 필터에 activation function이 적용이 되므로 nonlinear function이 되고 따라서 network 내부에 layer을 붙일 수 있어서
end-to-end방식으로 학습이 가능하게 된다. 이러한 이점 때문에 논문에선Deconvolution기법을 활용한 unsampling을 수행하게 된다.
Patchwise training is loss sampling
patchwise방법이나fully convolutional방법이나 data가 어떤 분포를 형성하는 것은 같지만patchwise방법에서 patch들 간에 overlab(중복)과 minibatch size의 수에 따라서 불필요한 computation양이많아진다고 말한다.
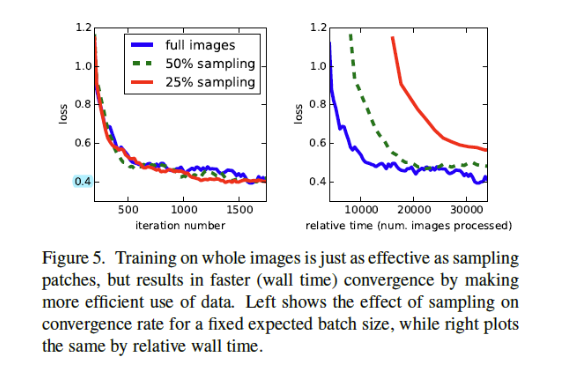
fully convolutional방식 보다patchwise방식을 적용했을 때 loss가 잘 수렴한다던지의 장점은 없기 때문에fully convolutional하게 전체 이미지를 입력으로 받아 training을 하는 방식을 채택했다고 설명한다.
Segmentation Architecture
- 이젠 FCN의 구조에 대해서 자세히 알아볼 것이다.
- 본 논문에서는 AlexNet, VGG, GooLeNet의 pre-trained된 net의 classification 부분을 fc를 fcn으로 대체하여 사용했고 segmentation을 학습시킬 때 pre-trained 부분을 fine-tuning을 시켰다(PASCAL VOC 2011).
-
그 결과
mean IOU의 결과로 측정했을 때VGG의 결과가 제일 잘 나왔다.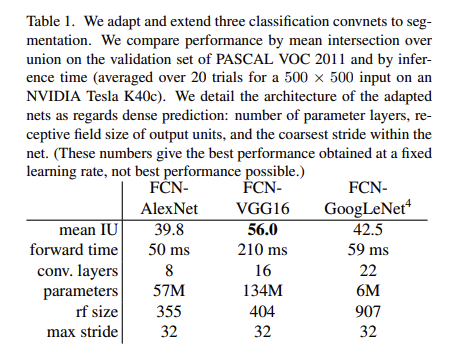
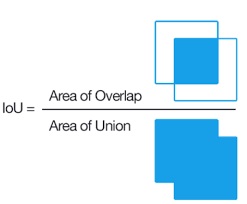
IOU는 1에 가까울 수록 좋은 성능을 가졌음을 의미한다.
-
그리고 실험한 모델 중 가장 성능이 나쁜 모델 조차도 당시 SOTA에 해당하는 모델의
75%정도의 좋은 성능을 보여줬고FCN-VGG16모델이 segmentation 결과SOTA의 성능을 냈다고 한다.
Combining what and where
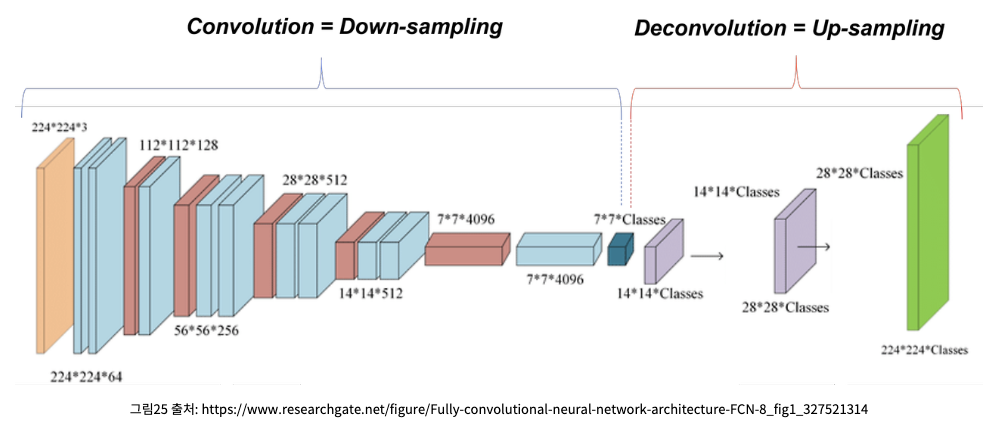
- 지금까지 설명한 FCN의 구조는 이렇다. 이 구조만으로 segmentation을 적용하면 성능이 좋지 않기 때문에(FCN-32s) 논문에서는
skip architecture기법을 적용하여 최종 FCN 모델 구조를 고안했다고 한다.
- 깊은 레이어의 upsampling이 디테일에 한계가 있어서 얕은 레이어와 결합을 하면 전역 정보와 지역 정보를 함께 가져가는 구조가
skip architecture이다. 따라서 final prediction layer와 더 낮은 스트라이드를 가진 lower layer를 결합하는 링크를 추가하여skip architecture를 완성 시킨다.
- 1x1인 pool5의 activation map을 32배 한 upsampled prediction이 FCN-32s
- 2x2인 pool4의 activation map과 pool5를 2x upsampled prediction을 더하면 16x upsampled prediction(FCN-16s)
- 4x4 pool3과 앞서 더해주었던 prediction을 합하면 8x upsampled predicton(FCN-8s)
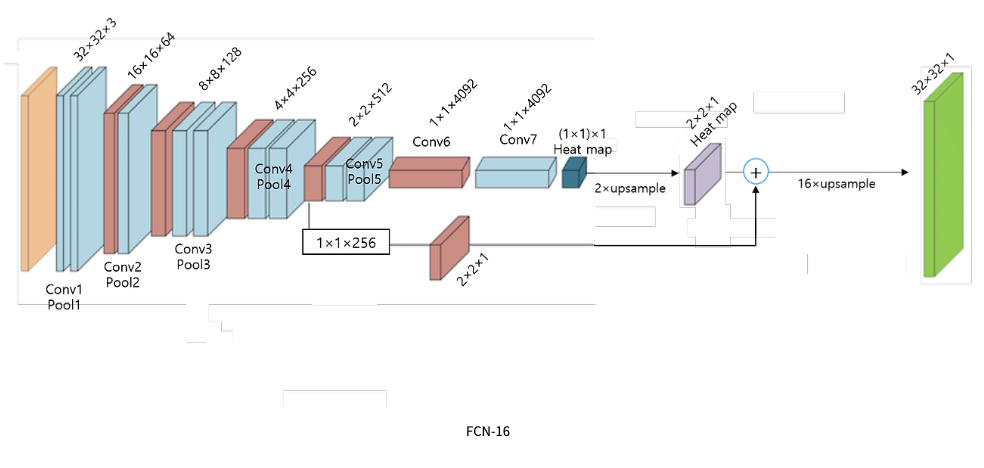
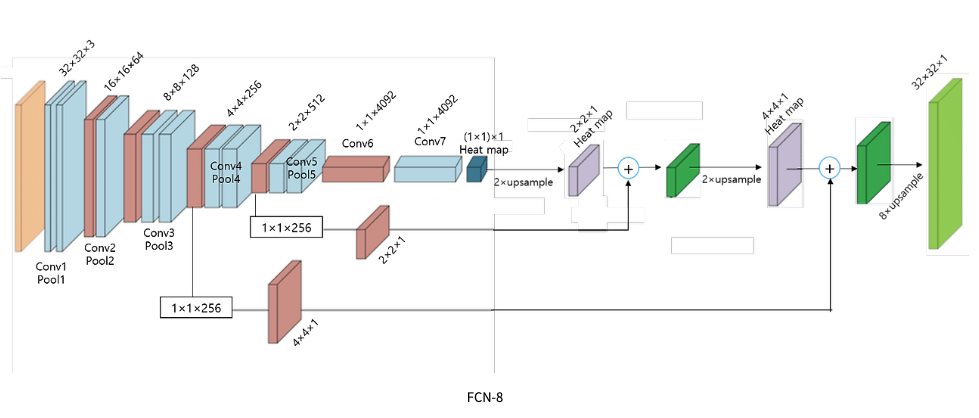
-
따라서 이런
skip architecture를 통하여fcn-8이 큰 성능 향상을 이루었다.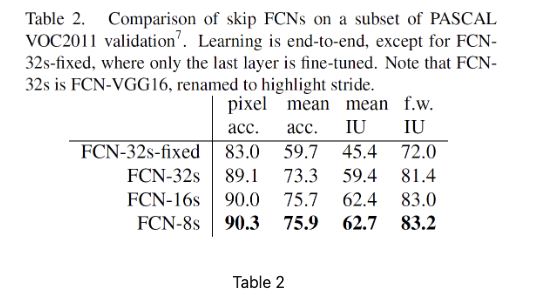
-
그 후
Experimental framework파트에서는 실험을 할 때 사용했던optimization, fine-tuning, patch sampling, class balancing등등 실험 했던 것을 나열하고 있다. 이에 관한 더 자세한 사항은 논문을 참고하면 좋을 것 같다.
Implement
- 코드에 대한 구현은 여기에 해두었다.
VGG16 & FCN-8s으로 구현 하였다.
Reference
- https://lee-jaewon.github.io/deep_learning_study/FCN/
- https://jlog1016.tistory.com/84
- https://89douner.tistory.com/296
- https://89douner.tistory.com/m/296?category=878997
- https://medium.com/@msmapark2/u-net-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-u-net-convolutional-networks-for-biomedical-image-segmentation-456d6901b28a