[Paper Review]Fast R-CNN
Contents
개요
Object Detection분야에서 널리 사용되는 딥러닝 모델인Fast R-CNN에 대한 논문 리뷰를 해보려고 한다.
- 이번
Fast R-CNN은R-CNN의 단점을 고안하고자 나온 모델이다.
Introduction
- 본 논문이 나온 시기의 detection은
classification보다 더 복잡한 모델로 해결을 했는데multi stage pipeline을 가진 모델들은 slow하고inelegant하다.
- 이런 complexity는 object의
localization때문에 일어난다.
- 이는 두가지 문제점을 지니고 있는데
- 수많은 후보 object들이 제안된다
- 이 후보들이 정확한
localization을 하기 위해 다시refine해야 된다.
- 따라서 본 논문에서는 이전
R-CNN과는 달리single-stage(분류하고 공간 정보를 강화하는) 훈련 기법을 제안한다- VGG16을 사용했으며
R-CNN보다 9배 빠르고,SppNet보다 3배 빠르다.
- VGG16을 사용했으며
- 그리고 논문에서는 이전 모델인
R-CNN의 몇가지 단점을 설명한다.
-
훈련 시
multi-stage pipeline이다.object proposals을 cnn을 통하여특징 추출을 하고- 그것들의 feature를
svm이분류를 해주고 - 마지막으로
bounding box regressor를통해3단계를거친다.
-
훈련 시 공간과 시간적으로 낭비가 된다.
- svm, bounding-box regressor를 할 때,
오버헤드가 심하다
- svm, bounding-box regressor를 할 때,
-
마지막으로 이미지를 test를 할 때 이미지당 47초가 걸린다.
R-CNN은 계산량 공유 없이 각각의 object마다 계산을 해서 오래걸린다.
SppNet은이러한 점을 극복했다.SppNet은 전체 이미지의feature map을 계산 한 후 거기서 각각의object proposal을 분류 한다.
- proposal을 위해 feature에서 고정된 크기로 추출한다. 그리고 다중 출력 크기로 추출한 다음 그것을
spatial pytamid pooling에서 합친다.
- 이를 통해 테스트 시간(10~100배)과 훈련 시간(3배)을 크게 줄일 수 있습니다.
- 근데 이러한
SppNet도 단점이 있다. 여러 단계를 거친 pipeline이라는 것이다.
- 하지만
R-CNN과 달리,SppNet에서 제안된 미세 조정 알고리즘은 공간 피라미드 풀링 이전의 합성곱 층들을 업데이트할 수 없다.
- 이러한 제한 사항(고정된 합성곱 층들)은 매우 깊은 네트워크의 정확도를 제한한다. 따라서 이런 단점들을 보안하고자
Fast R-CNN을 고안했다.
Fast R-CNN은 몇가지 장점이 있다.- 다른 것들 보다 높은 mAP(점수)
multi task loss를 사용한single-stage훈련 기법- 모든 network layer가 update된다.
- 특징 추출에
disk storage가 필요하지 않다.
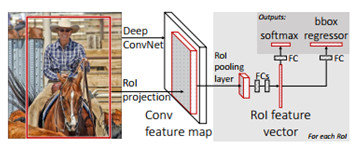
- 사진은
Fast R-CNN의architecture의overview이다.Fast R-CNN은 input으로 전체 이미지를 넣고 그와 함께object proposal (selective search로 구해둠)의set을같이 넣는다.
- 그럼
network는여러conv를거쳐conv feature map을 생성한다. 그럼 각각의RoI pooling layer은 추출한다. 고정된 크기의feature vector가 생성이 된다. (ROI들은 각각 다른 크기를 지녔기 때문)
- 그 후
Fully Connected (FC)층으로 가며 이것은 또2가지 분기로나뉜다.- 하나는 (K +1 class의)softmax 확률 추정치를 구한다
- 다른 하나는
각 K 개의 객체 클래스에대해 4개의 실수 값을 출력합니다. 4개의 값 집합 각각은 K 개 클래스 중 하나에 대한 세밀한 바운딩 박스 위치를 인코딩합니다.
RoI pooling layer
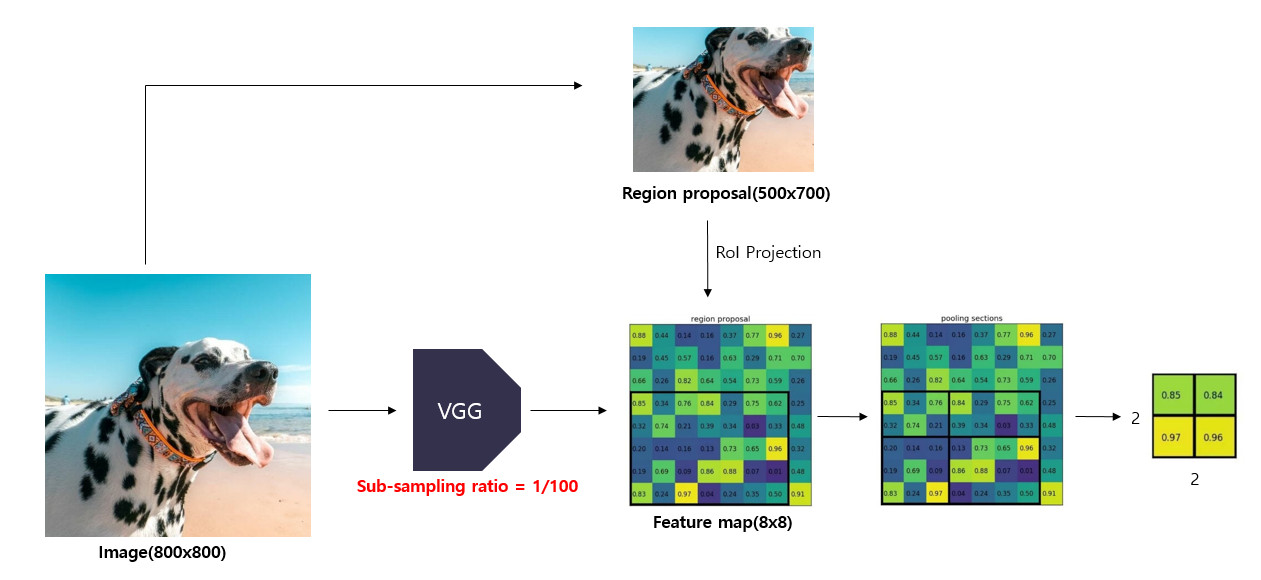
RoI pooling layer는max pooling을 사용하여region of interest(RoI)를 고정된 크기의 spatial small feature map으로 변환한다.
Selective search를 통해resion proposal을 얻게 된다.
- 이때
spatial small feature map의 $H, W$의 값은특정 RoI와는 독립적인 하이퍼 파라미터이다.
RoI는 합성곱 특징 맵(conv feature map) 내의 사각형 창을 의미합니다.- 각각의
RoI는**(r,c,h,w)**의 특징을 지니고 있는데 **(r,c)**는top-left를 의미하고 height와 width는(h,w)를 의미한다.
- 각각의
RoI max pooling은 $h × w$ 크기의RoI 창을 $h/H × w/W$ 크기의 grid를 만든다.
- 그 후 grid에
max pooling하여 해당 $H × W$ 크기의출력 grid 셀에 넣는 방식으로 동작합니다.
Pooling은 표준max pooling에서처럼 각feature map channel에 독립적으로 적용됩니다. 이는Sppnet에서하나의 pyramid level만 사용한 것과 동일하다.
- 결론적으로 원래 이미지를
CNN에통과시킨 후 나온feature map에이전에 생성한RoI를projection시키고, 이RoI를FC layer input크기에 맞게 고정된 크기로 변형할 수가 있다.
- 이를 통해
RCNN처럼 2000번의 CNN연산 필요 없이, 단한번의 연산으로속도를 대폭 높일 수 있게 된다.
Initializing from pre-trained networks
본 논문에서는3가지의 network변화를 주었다.
-
첫 번째는 Last max pooling layer가
RoI pooling layer로 변경fc층과 상호작용할수 있게 H,W가 세팅되어 있다
-
두 번째는 마지막 fc층의 변경이다
- 2가지
자식 layer로분기가 된다- 하나는
확률 분포 - 하나는
bounding box regressor
- 하나는
- 2가지
-
세 번째는
input data의 수정이다. 다음의 두개가 input에 들어가게 한다.- list of image
- list of RoI
Fine-tuning for detection
R-CNN이나 SPPNet에서spatial pyramid pooling layer에서weight가 update가 되지 않는 이유를 설명 할 것 이다.
R-CNN에서는 CNN을 통과한 후 각각 서로다른 모델인SVM(classification),bounding box regression(localization)안으로 들어가forward됐기 때문에연산이 공유되지 않는다.
- 하지만
Fast R-CNN에서는RoI pooling을 추가하여 CNN을 통과한 후의feature map을 투영시킬 수 있게 되었다.
Multi-task loss
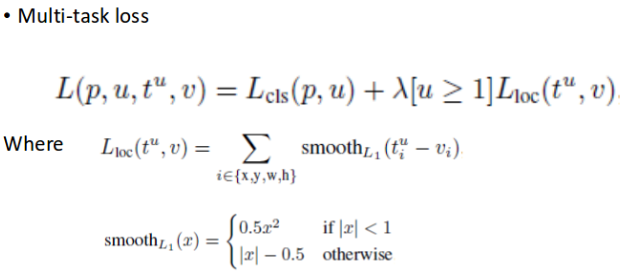
Fast R-CNN의Loss function은 위와 같이classification과localization loss를 합친 function으로써 한 번의 학습으로 둘 다 학습시킬 수가 있다.
R-CNN모델과 같이각 모델을 독립적으로 학습시켜야 하는 번거로움이 없다는장점이있습니다.
multi task loss는0.8~1.1% mAP를 상승시키는 효과가 있다고 합니다.
Truncated SVD for faster detectionm
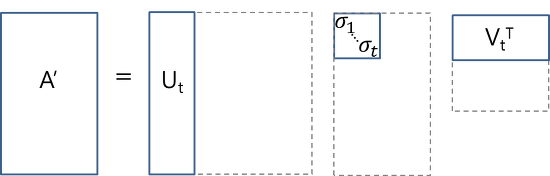
특이값 분해(SVD)를 활용하여 연산 시간이 오래 걸리는 FC층을 압축하는 방법을 제시한다.
Truncated SVD와 같이 분해된 행렬 중 일부분만을 활용하는reduced SVD를 일반적으로 많이 사용한다고 합니다.
- $W \approx U \Sigma_t V^T$ 처럼 W를 이 같은 식으로 분해가 가능하도록 한다.
- 따라서
Truncated SVD를 통해fc layer의 가중치 행렬이 $W( u* v)$라고 할 때, 파라미터 수를 $u*v$에서 $t(u + v)$로 감소시키는 것이 가능하다.
- 본 논문에서는
FC층이2가지 분기로 되어있는데 첫 번째FC Layer는 $\Sigma_t V^T$ 가중치 행렬, 두 번째FC Layer는 $U$가중치 행렬이다.
- 이를 통해
FC층을 효율적으로 압축하고 detection 시간이 30% 정도 감소되었다고 말한다.