[Paper Review]Training data-efficient image transformers & distillation through attention(DeiT)
Contents
개요
ViT의 단점을 보완하고자 나온 논문인DeiT에 대한 리뷰를 할 것이다.
Abstract
Convolution Neural Networks은image classification에서 대규모 훈련 세트를 같이 사용한 주요 설계 방식이었다.
- 점점 NLP에서도 attention 기반 모델들의 사용이 많아지고 있었다. 따라서
Vision분야에서도attention기반과CNN을 합치는 하이브리드 아키텍쳐가 있었다.
- 그 결과
ViT가 나오게 되었는데 이는 3억 개의 사설 라벨 이미지 데이터셋으로 학습을 했다.
ViT의 논문에서는 Do not generalize well when trained on insufficient amounts of data으로 설명을 하였고 이를 위해선 방대한 컴퓨팅 자원이 필요했다.
- 따라서 본 논문에서는
ViT보다 훨씬 적은 데이터로 학습된Data-efficient image Transformer(DeiT)모델을 제시한다.
- 적은 데이터로 학습을 하기 위해서
Knowledge Distillation의 방법을 사용하며 그것을 이루기 위하여token-based방식을 취한다.
- 본 논문에 나온 연구를 요약하자면 다음과 같다.
- 이번
DeiT는CNN이 없는neural network가 외부 데이터 없이 ImageNet의 훈련만으로SOTA들과 경쟁을 할 수 있게 된다. Distillation token의 기반으로지식 증류를 하여 기존 증류 방식보다 현저히 더 우수한 성능을 보여준다.전이 학습을 할 때 경쟁력을 유지하는 성능을 보여 일반화가 잘 되어있다는 것을 알 수 있게 된다.
- 이번
Vision transformer: overview
- 다음 내용은 본 논문에서 기반을 둔 아키텍쳐인
ViT에 관한 간략한 요약에 관한 내용들이다.
- 이 내용들은
ViT논문 리뷰에서 정리를 해두었으니 자세한 내용은 해당 리뷰를 가서 확인 하면 될 것 같다.
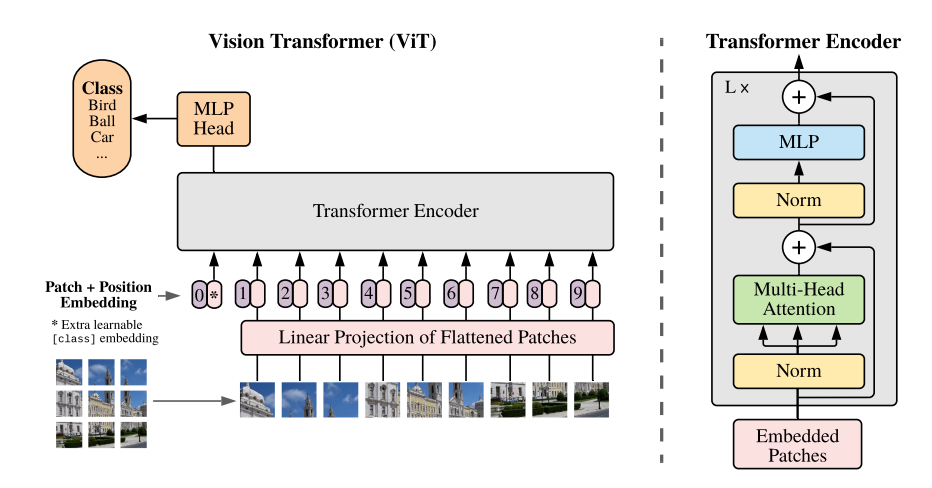
ViT의Multi-head Self-Attention,Transformer Block 구성,Class token에 대한 설명이 나와 있다.
- 또한 더 낮은 해상도로 훈련하고 더 높은 해상도에서 네트워크를
fine-tuning하는 것이 바람직하다고 나온다.
- 이 방법은 전체 훈련 속도를 높이고 데이터 증강 방식에서 정확도를 향상시킨다. 해상도를 높이고 훈련을 다시 할 때 패치 크기는 동일하게 유지하므로 입력 패치의 개수는 변하지 않지만 위치 임베딩은 조정이 필요하다.
- 따라서 해상도를 변경할 때 위치 인코딩을
interpolate하는 방법을 사용한다.
Distillation through attention
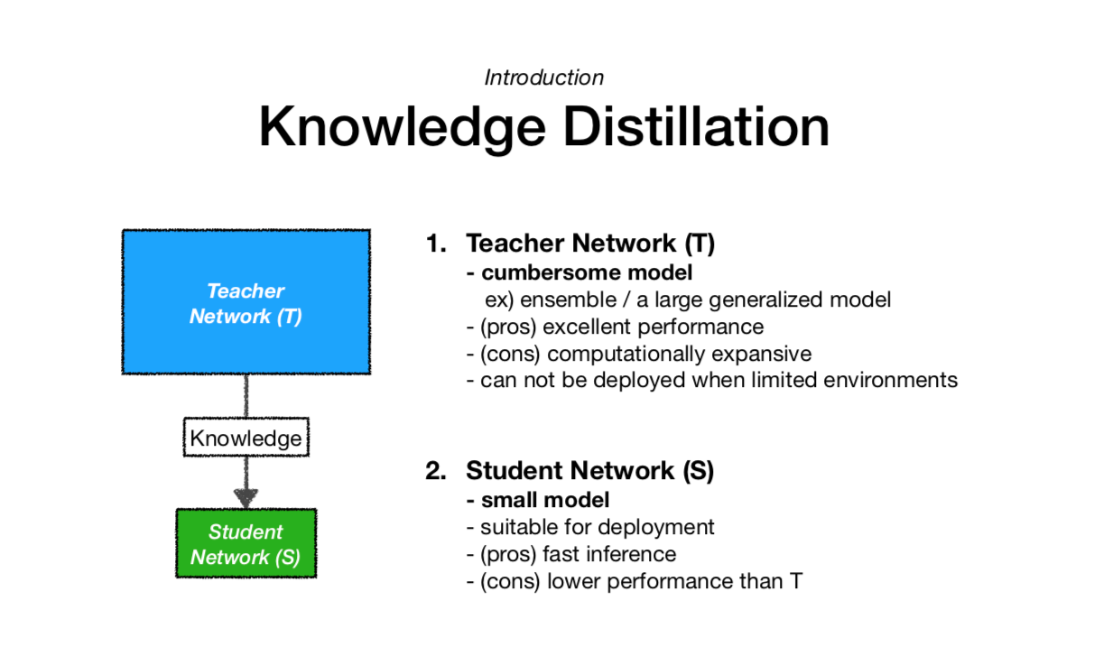
- 이번 내용은
Knowledge Distillation을 통해ViT를 학습시키는 방법에 대해서 설명을 한다.
- 방법에 대해서 설명하기 앞서
Knowledge Distillation의 기본 개념인Soft distillation과Hard-label distillation에 대한 설명을 한다.
$$L_{\text{global}} = (1 - \lambda) L_{\text{CE}}\left( \psi(Z_s), y \right) +\lambda \tau^2 \text{KL}\left( \psi\left(\frac{Z_s}{\tau}\right), \psi\left(\frac{Z_t}{\tau}\right) \right)$$
Sort distillation은 위 식과 같이Cross entropy loss를 사용하고 교사 모델 loss($Z_t$)와 학생 모델 loss($Z_s$)를 온도 $\tau$를 사용하여 증류를 한다.
$$L_{\text{global}}^{\text{hardDistill}} = \frac{1}{2} L_{\text{CE}}\left( \psi(Z_s), y \right) + \frac{1}{2} L_{\text{CE}}\left( \psi(Z_s), y_t \right)$$
- 또한
Hard distillation은 실제 레이블로 변형한 형태로 argmax 함수로 표현을 하는데 이는 특정 이미지에 대해 교사와 관련된 하드 라벨은 특정 데이터 augmentation 방법에 따라 변경이 될 수 있다고 한다.
- 또한
Hard distillation에Label Smoothing기법을 사용하여 훈련 데이터의 레이블에 약간의 불확실성을 추가를 하여Soft distillation으로 변형할 수도 있다고 한다.
Label Smoothing을 적용하면 원래 레이블이 $[1,0,0]$이라면 $[ 1 - \epsilon, \frac{\epsilon}{K - 1}, \frac{\epsilon}{K - 1}]$ 으로Soft distillation이 가능하게 변경될 수 있게 된다.- 이를 사용하면
과적합 방지,일반화 성능 향상,손실 함수 안정화의 장점을 얻게 된다.
- 이를 사용하면
- 본 논문에서는 $\epsilon = 0.1$로 설정하여 훈련을 진행하였다고 한다.
Knowledge Distillation
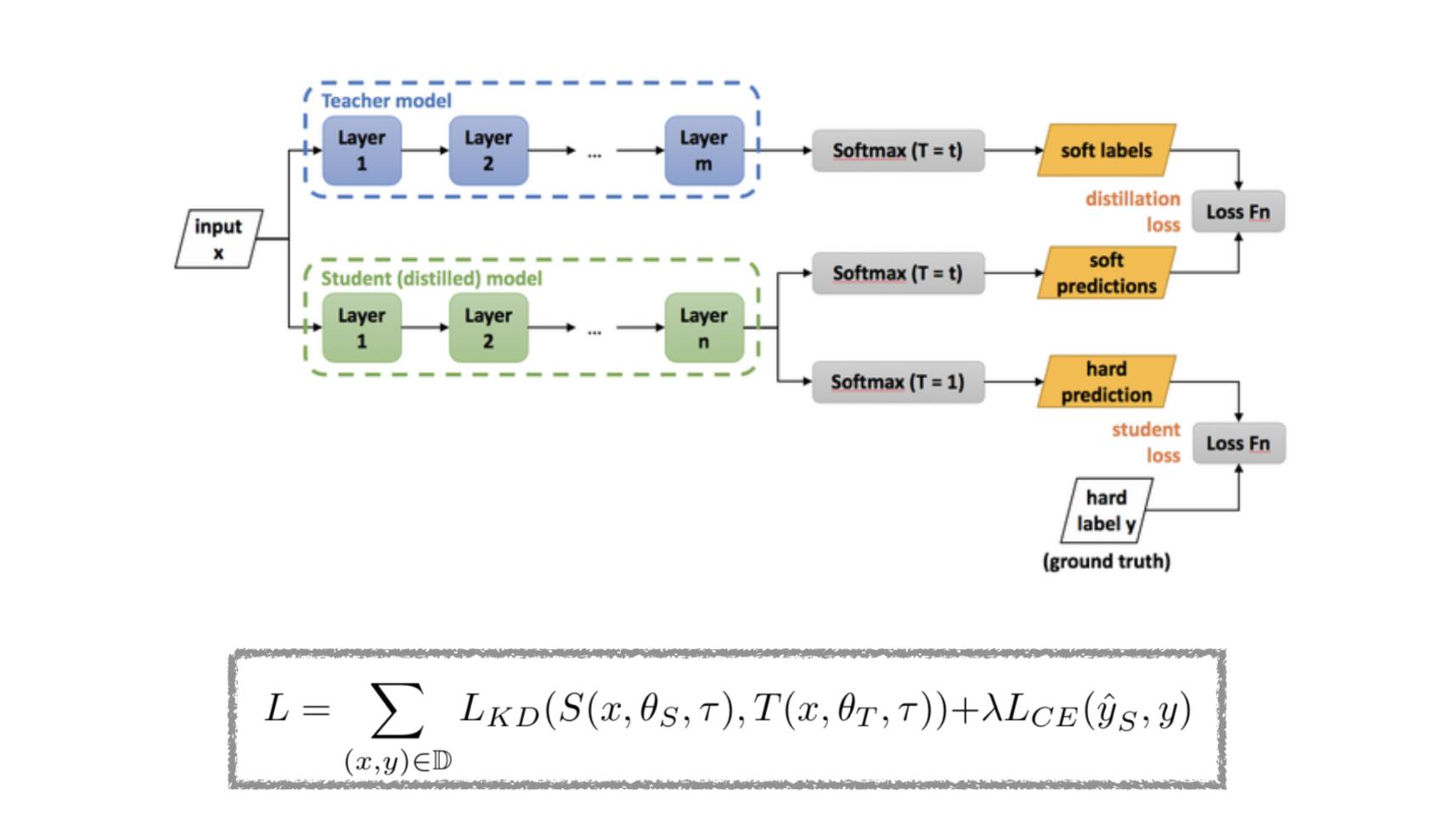
- 추가적으로
Knowledge Distillation에 대해서 알아보자면 딥러닝에서 지식 증류는큰 모델(Teacher Network)로부터 증류한 지식을작은 모델(Student Network)로transfer하는 일련의 과정이라고 할 수 있다.
- 이는
방대한 양의 데이터로 학습한 모델을model deployment의 관점으로 봤을 때더 가벼운 모델을 만들기 위하여복잡한 모델의 일반화 능력을 가벼운 모델에게transfer하는 것을 말한다.
Transfer하는 방법은위 그림의 오른쪽 윗 부분이 있는데Teacher와Student의output을loss fn으로 계산하고 있다. 또한 오른쪽 아래 부분은Student의hard prediction을Ground truth와loss fn을 계산하는 구조가 보인다.
- 이때 Teacher에서 loss를 계산할 땐
Hard label이 아닌Soft label을 사용하고 있는데 왜냐하면Hard label을 사용한다면 argmax 함수를 사용하여 다른 정보들이 사라지게 된다.
Hard label: $Bear, Cat, Dog = [0, 1, 0]$Soft label: $Bear, Cat, Dog = [0.05, 0.75, 0.2]$
- 따라서 이러한 정보의 손실 없이 확률값을 그대로 loss를 계산할 때 사용을 하여
Student를 업데이트 시키는데 하이퍼 파라미터의 설정을 통하여 왼쪽항과 오른쪽항에 대한 가중치인 $a$, Softmax 함수가 입력값이 큰 것은 아주 크게, 작은 것은 아주 작게 만드는성질을 완화 해주는Temperature(T)를 사용하여Soft label을 사용하는 이점을 최대화 한다.
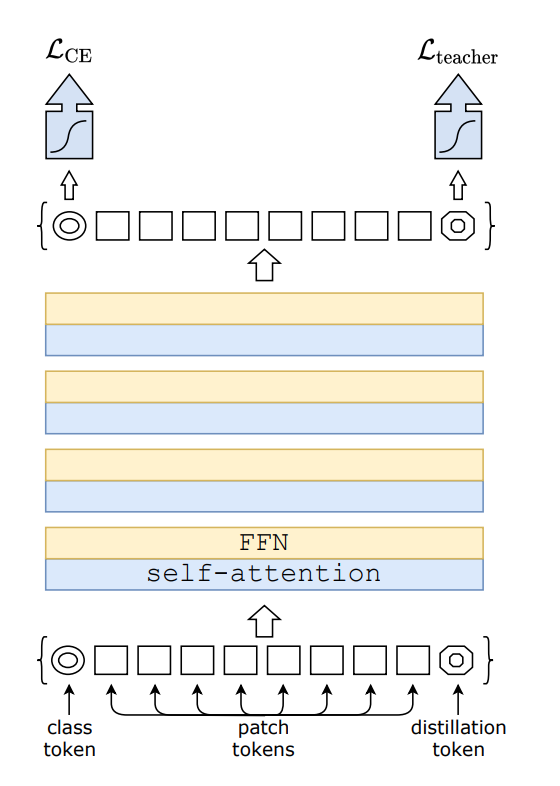
- 다음은
본 논문에서 본격적으로Knowledge Distillation을 사용한 방법에 대해서 설명을 할 것이다.
DeiT에서는Class Token과 유사하게 사용되는Distillation Token이라는 것을 추가하였다.
- 이 토큰은
Class Token과 유사하게self-attention을 통해 상호작용을 하며 마지막 레이어를 지나 출력이 된다.
- 이
Distillation Token의 역할은 모델이Distillation embedding을 통하여 교사의 출력을 학습하도록 도와주는 역할을 한다. 즉, Student가 Teacher의 출력을 배우는 역할을 하게 된다.
Class Token은 이미지가 어떤 클래스에 속하는지 예측하기 위해 사용되는 반면,Distillation Token은Teacher의 지식을 학습하기 위해 사용되어Class embedding과는 별도로 학습이 된다.
- 따라서 논문에서는
Class Token과Distillation Token이 서로 다른 벡터로 수렴하는 것을 관찰했다. 마지막 레이어에서의cosine similarity는0.93으로 유사했다고 나온다. 하지만 두 벡터가 유사하지만 동일하지는 않으려는 목표를 가지고 있어서 1보다는 낮게 관찰이 된다.
- 또한
Class Token을단순히 추가한 것(2개)과 비교해보았을 때 단순히 추가하면 마지막 레이어에서 출력 임베딩의cosine similarity가0.999로 거의 동일하고 추가된 Class Token이 성능에 아무런 기여를 하지 않은 것으로 확인이 되었다.
- 반면
Distillation Token은 성능에 상당한 기여를 하였다.
Fine-Tuning을 진행하였을 때도Teacher의 예측을 모두 사용하여 성능에 이점을 보였다고 한다.
Fine-Tuning을 진행하면서도knowledge distillation을 사용했다.
- 또한 마지막 output인
Class embedding과Distillation embedding모두 이미지를 분류할 수 있게 되는데 본 논문에서는 두 분류기의 출력을late fusion방식을 사용하여 예측을 수행한다.
Late Fusion: 다중 소스의 정보를 결합하여 최종 예측을 생성하는 기법이다.
Code
- DeiT의 model code를 살펴보니 기존
ViT의 형식에cls token과distillation token이 함께 부착을 했다는 것을 확인할 수 있다.
# forward_features Functions
cls_tokens = self.cls_token.expand(B, -1, -1)
dist_token = self.dist_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, dist_token, x), dim=1)
x = x + self.pos_embed