[Paper Review]DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs(DeepLab V2)
Contents
개요
DeepLab V1에 이어서DeepLab V2에 대한 논문 리뷰를 해보려고 한다.
V1과 엄청나게 큰 차이는 없지만 방법론의 변화가 있었다.
Abstract
- 본 논문에서 해당 모델(DeepLab-V2)에서 사용하고 있는 세가지의 주된 방법을 설명하고 있다.
- 첫 번째로
Atrous convolutional이다. 이는 파라미터의 수 증가 없이 더 많은 context들을 포함하여 FOV(Field of View)를 증가 시킨다.
- 두 번째로
Atrous spatial pyramid pooling (ASPP)이다. 이는 multi scale로 image context를 다양한 context들을 효과적으로 포착이 가능하다.
- 따라서
ASPP를 사용하게 되면 더욱robust하게 객체를 분할 할 수 있다고 설명한다.
- 세 번째로
Conditional Random Field (CRF)이다. 이는 max-pooling, downsampling의 결합이 배치되어invariance가 있던 것들을 CRF를 사용하면서 질, 양적으로 localization 성능을 향상시킨다고 나온다.
Introduction
hand-crafted feature보다 더 좋은 성능을 나타내기 때문에Deep Convolutional Neural Networks (DCNN)이 classification, object detection에서 많이 사용된다.
- 이러한 성공을 이끈 것은 image 변형에 대한 추상적인 data representation을 학습하게 하는 built-in invariance(불변성)이다.
- 하지만 이런 invariance는 classification task에는 좋지만 spatial information이 undesired한 segmentation에는 좋지 않다.
- 따라서 본 논문에서는 이런 단점을 극복하기 위해 아래 세가지 사항을 고려 했다.
- reduce feature resolution
- existence of object at multiple scale
- reduce localization accuracy
- 첫 번째 challenge는 max-pooling과 downsampling이 반복되어서 나타낸다. 이는 spatial resolution을 줄이기 때문에 안좋다.
- 이를 해결하기 위해서 우린 맨 마지막 단의 몇개의 maxpooling layer를 제거하고 높은 sampling 비율(더 높은 해상도)로 계산하기 위하여 대신에 upsample 하는 filter를 추가한다.
- 이때 filter는
hole algorithm을 사용한atrous convolution을 추가한다.
- 실제 atrous convolution과 hole algorithm을 사용하여 계산량을 증가시키지 않고
FOV를 증가시켰다.
- 두 번째 challenge는 기존의 방법은 동일한 이미지를
rescale 버전을 DCNN에 입력한 후 얻은 feature map을 aggregate한다.
- 이 방법은 performance는 증가하지만
computing overhead가 발생한다.
- 따라서 본 논문에서는
spatial pyramid pooling (SPP)을 사용하여 convolution 전에 주어진 feature layer를 resampling 하는 효율적인 구조를 제시한다.
- 이것은 원본 이미지를 여러(Multiple) 필터로 보는 것과 같아서 효율적인 FOV, useful한
multi scale의 관점에서 다양한 image context를 포착할 수 있다.
- 우린 병렬로 atrous convolutional layer를 사용한다. 이를 ‘atrous spatial pyramid pooling’ (ASPP)라고 불린다.
- 세 번째 challenge는 object-centric classifier는 공간적 변형에 대한 불변성이 필요하다.
- 이를 해결하기 위해선 마지막 segmentation결과를 계산하기 위한
hyper-column의 특징을 뽑는 skip layer를 사용하여 해결한다.
- 미세한 edge detail을 포착하기 위하여
fully connected pairwise CRF를 사용한다. 또한, CRF랑 DCNN이랑 연결했을 때SOTA를 달성했다.
- 마지막으로 따라서 본 논문에서 DCNN 모델로
VGG-16,ResNet-101을 사용했고Fully convolutional한 층을 사용하였다.
Methods
- 앞에서 말한 세가지 방법에 대해 좀 더 자세히 설명하도록 하겠다.
Atrous Convolution for Dense Feature Extraction and Field-of-View Enlargement
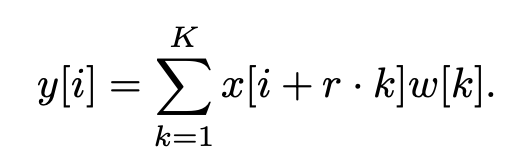
x[i]: inputw[k]: filter (length: K)r: rate,stride
- 1차원에서
atrous convolution의 기존 식은위 그림과 같다.
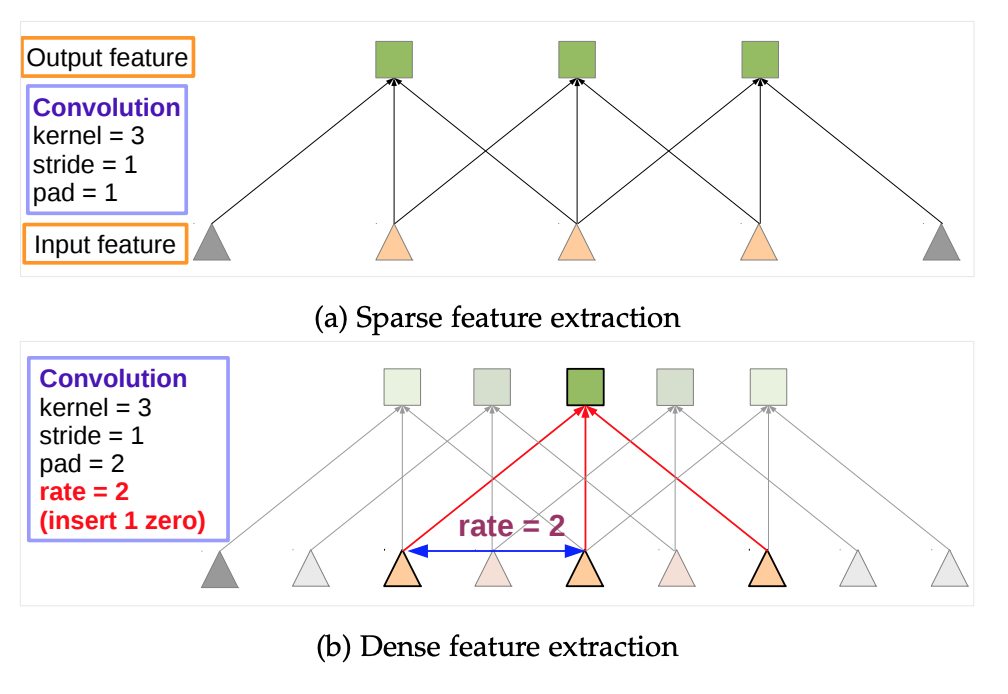
- 하지만
atrous convolution을 사용 하기 위해위 그림과 같이 r의 값을 조절하여 high resolution input feature map에도 사용할 수 있다.
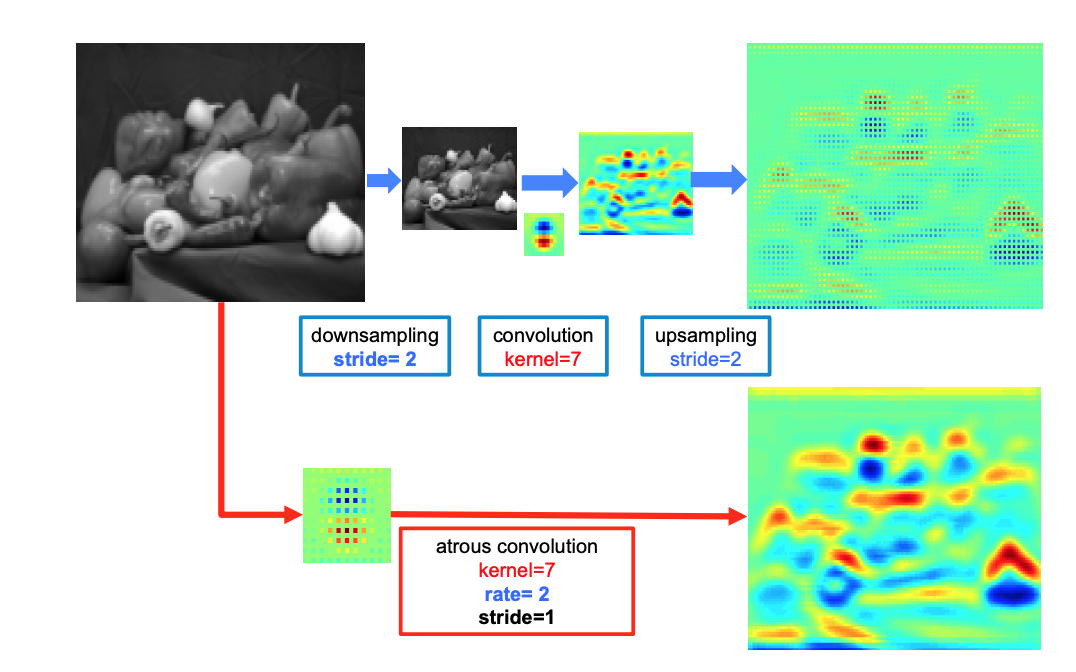
- 또한
위 그림처럼 2-D일때의 feature map의 특징을 보면 더욱 뚜렷한 것을 확인할 수 있다.
- 기존 방식대로 커널을 사용하게 된다면 1/4 의 이미지의 위치에 있는 데이터만 얻을 수 있게 된다. 하지만 atrous convolution을 사용하게 된다면 모든 이미지에 대한 정보를 얻을 수 있기에 spatial resolution이 증가한다.
atorous convolutional layer를 모든 층에 사용하기엔 비용적 오버헤드가 발생하여하이브리드 전략을 취한다.
- 따라서 본 논문에서는 마지막 풀링, convolution layer에
atrous convolution layer를 추가하여 (stride = 2) 4배로 늘리고, 이중 선형 보간법을 사용해 8배로 늘려 원래 이미지 해상도에서 특징 맵을 복원한다.
- 이런
atrous convolution은 어떤 레이어에서든FOV(field of view)를 임의로 확대할 수 있게 된다.
- 이런
atrous convolution을 구현하기 위한 방법으로는두가지 방법이 있다.
첫 번째 방법으로는 필터를 업샘플링하여 구멍(0)을 삽입하거나, 동등하게 입력 특징 맵을 희소하게 샘플링하는 것입니다. (input feature map에 0을 추가)
두 번째 방법으로는 입력 특성 맵을 atrous 합성곱 비율r에 해당하는 비율로샘플링(subsample)하는 것이다.
- r×r 가능한 시프트 각각에 대해 해상도가 줄어든 r^2개의 맵을 생성
- 중간 특성 맵에 표준 합성곱을 적용하고 이를 다시 원래 이미지 해상도로 재조립합니다(reinterlace)
- atrous 합성곱을 일반 합성곱으로 변환함으로써 최적화된 합성곱 루틴을 사용할 수 있게 된다.
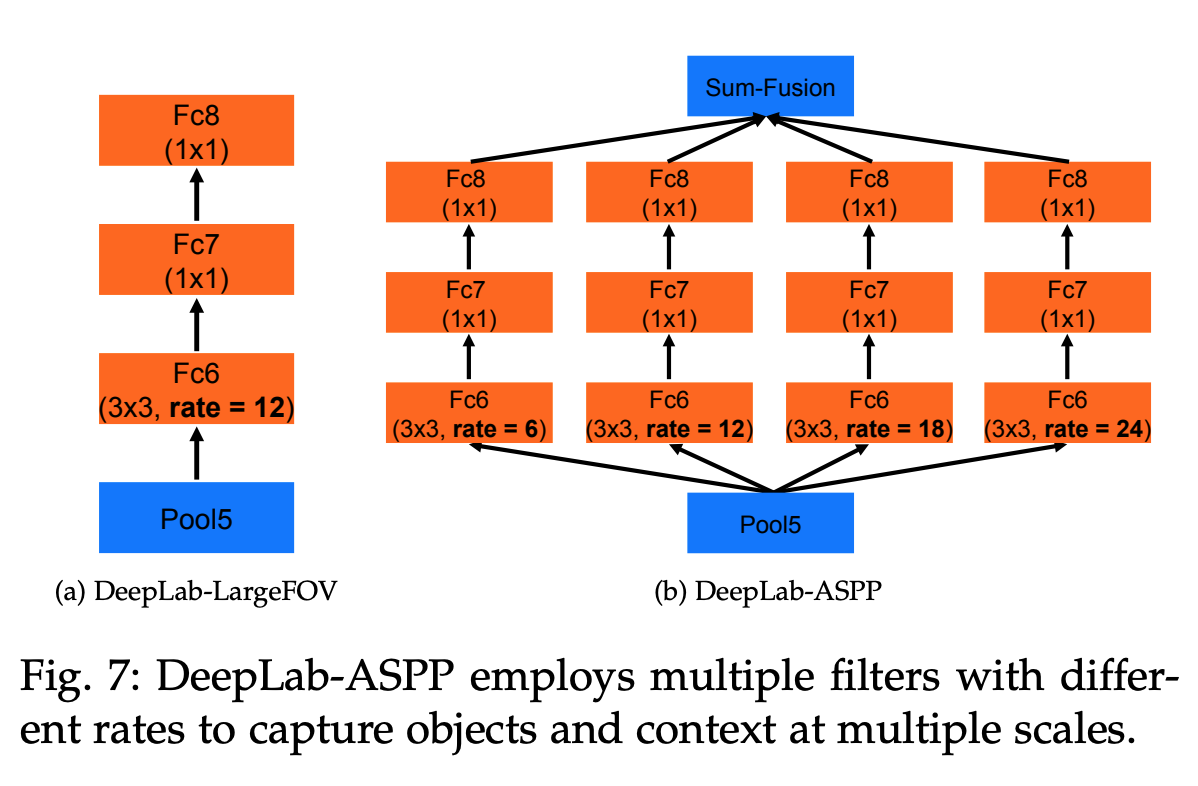
Multiscale Image Representations using Atrous Spatial Pyramid Pooling
- 다음으론
Atrous Spatial Pyramid Pooling (ASPP)에 관한 설명이다.DCNN은다양한 size의 object를 포함하고 있다. 따라서segmentation에서 사용하기 위하여2가지 방법을 사용한다
첫번째 방법으로는 다음과 같다.standard multiscale processing을 계산한다.- 같은 parameter를 공유하는 DCNN branch를
병렬로 3개의 version을rescale한다. - 이를
이중선형 보간을 한다. 그리고 이를융합(fuse)한다. - 이 방법을
training, testing둘다 사용 한다. - 하지만 그만큼의 computing resource의 문제가 있다.
-
두번째 방법으로는 다음과 같다.- R-CNN의 방법에서 영감을 얻어
SPP(임의의 scale의 지역을single scale의 conv 특징을resampling하면서 정확하고 효율적이게 분류하는 방법)의 방법을 사용한다. 다른 sampling rate별로 병렬적으로 multiple 한atrous conv layer를 사용하는 구조를 지닌 불변성을 구현했다.- 특징 추출은
각각의 sampling rate 별로이루어지고 각각 다른 branch로 진행된다. - 최종 결과를 만들기 위해
융합(fuse)된다.
- R-CNN의 방법에서 영감을 얻어
-
논문에는 없지만 아래에서
SPP에 대해서 좀 더 알아보겠다.
Spatial Pyramid Pooling (SPP)
- 기존 CNN에서는 고정된 크기의 이미지만 입력으로 받았다. 그 이유는
Fully-Connected layer(FC)때문이었다.
- 이는 필터가
슬라이딩 윈도우 방식으로 훑어가는Object Detection에서 치명적인 단점이었다.
- 왜냐하면 필터로 탐지되는 객체의 크기는 다양할 수 있기 때문이다.
- 이를 해결하기 위하여
Spatial Pyramid Pooling (SPP)방법이 고안되었다.
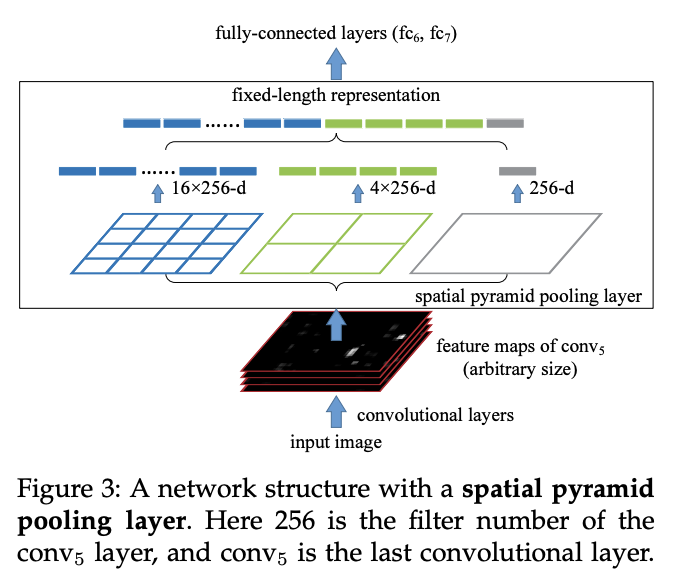
위 그림처럼arbitrary(임의의)한input이 들어와도피라미드 풀링을 하면 feature를 고정적인 사이즈로 압축이 가능 한 것을 확인 할 수 있게 된다.
- 이렇게 다양한 사이즈로 풀링을 진행하면, 정보(context)가 더욱 다양해지는 효과가 있습니다. 다양한 사이즈의 객체를 검출하는 데에 유리한 장점이 있게된다.
- 따라서
위 그림처럼DeepLab-V2에서는 이러한SPP의 필터를atrous convolution filter로 변경한 구조를 제안했다.
Structured Prediction with Fully-Connected Conditional Random Fields for Accurate Boundary Recovery
- 다음으론
Conditional Random Fields (CRF)에 대한 설명이다.
Segmentation에서는localization문제를 해결했어야 했는데 이 문제를 해결하기 위해 이전 연구는두 가지 방향을 추구했다.
-
첫 번째는객체 경계를 더 잘 추정하기 위해 컨볼루션 신경망의 여러 레이어에서 정보를 활용하는 것이다. -
두 번째는사실상localization작업을 low-level 분할 방법에 위임하는super-pixel representation을 사용하는 것이다.
super-pixel: pixel들을 색 등의저레벨 정보를 바탕으로 비슷한 것끼리 묶어서커다란 pixel을 만드는 작업이다.- 따라서
super-pixel로 대상의 경계를 파악하여localization이 강화가 된다.
- 따라서
- 본 논문에선
localization문제를 해결하기 위하여CRF방법을 사용했는데 이 방법은DeepLab-V1에서도 사용을 한 방법이다. 이를DeepLab-V2에서 더욱 발전을 시켰다.
- 기존 연구에서는 공간적으로 가까운 노드들에게 동일한 레이블을 할당하는 방식을 취했다.
(short-range CRF)
- 이를 통해 노이즈가 있는 분할 맵을 부드럽게 만드는 데 사용되었다.
- 하지만 현대의 DCNN은 일반적으로 매우 부드럽고 균일한 분류 결과를 생성하기 때문에
short-range CRF가 좋지 않았다.
- 왜냐하면 목적 자체가 부드러워 지게 만드는 것이 아니라
localization을 해결하기 위함이기 때문이다.
- 따라서
short-range CRF대신fully connected CRF을 고안하여 성능 향상이 기여하였다.