[Paper Review]Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks(DCGAN)
Contents
개요
GAN논문 다음으로Generative분야에서 기초가 되는 논문인DCGAN에 관한 리뷰를 할 것이다.
Introduction
Unlabeled data를 통한 재사용 가능한feature representation을 학습하는 것은 활발한 연구이다.
Computer vision에서는 무제한의 양의image와video를 활용하여 좋은intermediate representation을 배울 수 있게 된다.
- 본 논문은 좋은
image representation을 얻기 위한 방법으로GAN을 훈련시키고 지도학습에generator와discriminator를 다시 사용하는 방법을 제안을 한다.
- 이런
GAN은likelihood를 최대화 하는데 매력적인 대안을 제공한다.
- 그들의 학습 과정에서
heuristic한cost function이 없어지는 장점을 얻게 된다.
GAN은unstable한 훈련 방법으로 알려져 있는데 종종output으로 무의미한 것 또한 나오게 된다.
GAN에서Discriminative와Generator에서 각각objective function를 통하여gradient를 업데이트 시켜주는 방향이 상이하기 때문에 간혹 오류가 난다.
GAN이 무엇을 학습하는지, 그리고multi-layer GAN의 중간 표현을 이해하고 시각화하려는 연구는 매우 제한적이다.
- 따라서 본 논문은 위의 몇가지 제약사항을 해결하는 몇가지
contribution을 제안한다.
- 제약을 두어
GAN을 훈련 시 더욱 안정적이게 하였다. Discriminative를image classification task로 훈련시켰는데, 이는unsupervised algorithm보다 더 좋은 성능을 보여준다.GAN이 학습한 필터를 시각화 하고, 특정 필터가 특정 객체를 그리는 방법을 학습했다는 것을 실험적으로 보여준다.Generator들이 생성된 sample의 의미론적을 쉽게 조작할 수 있는 흥미로운vector 속성을 가지고 있음을 보여준다.
Approach and Model Architecture
- 이미지를 생성하기 위해
CNN을 사용한GAN을 확장하는 것은 성공하지 못하였다.
- 이전에도
GAN에CNN을 적용하려는 시도는LAPGAN이 있었다.
LAPGAN의 저자들이 저해상도의 생성image를 반복적으로 upscale하는 것을 통하여 신뢰할 수 있는 방법을 고안하였다.
본 논문에서 또한CNN을 사용한GAN을 확장하는 것에어려움을 느꼈지만계속된 탐색 끝에 GAN을 확장하는데 적합한 구조를 찾았다.
- 우리의 주요 방법은
CNN구조를 적용하고 수정하는세가지주된 변화가 있다.
첫 번째 방법으로spatial pooling(such as maxpooling)을all convolutional net으로 변경하는 것이다. 이를 통하여Discriminative의spatial downsampling을 배우게 한다.
- 이 방법은
generator또한 적용을 하여, 그것의 고유spatial upsampling을 배우게 한다.
두 번째 방법으로는fully connected층을 삭제하는 것이다. 삭제하고Global average pooling을 사용한다.Global average pooling을 사용하는 것은 모델의 안정성을 높이지만 수렴 속도가 느리다.
- 기존
GAN은 모든 층이fully connected layer로 구성되어 있다.
Generator과Discriminator의 입력과 출력에 각각highest convolutional feature가 직접 연결을 하는 것이 잘 작동을 했다.
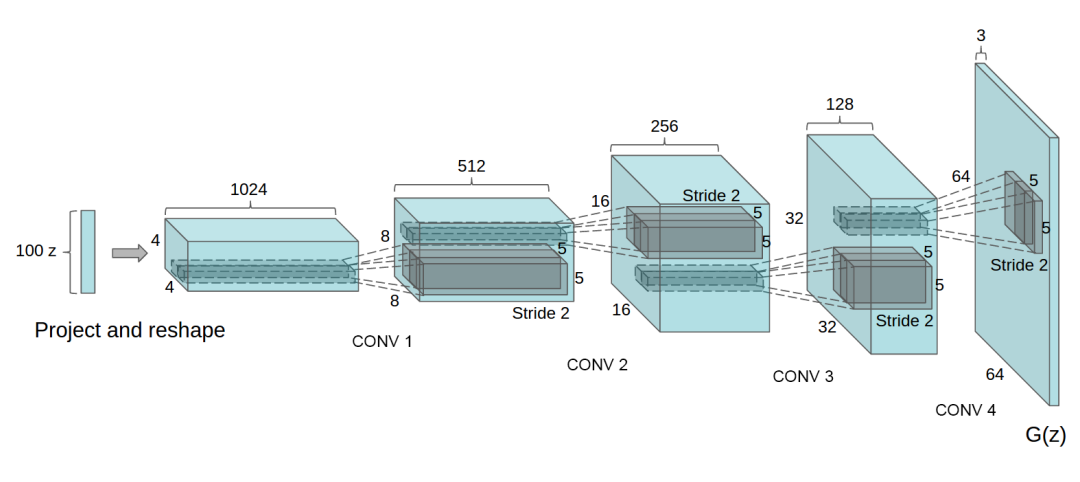
위 그림과 같이GAN의첫 번째 layer는uniform noise분포 $z$를 받게 되는데 이는4차원 텐서로 변환되고convolutional의 시작으로 사용된다.
Discriminative의 마지막convolutional layer은 flatten된 후,single sigmoid 출력으로 전달된다.
세 번째 방법으로는Batch normalization으로 input으로 들어오는 값을 평균 0, 분산 1로 정규화를 하여learning을 안정하게 하는 것이다.
- 이것은
poor initialization때문에 훈련 문제를 해결해주고 깊은 모델에서 gradient flow를 잘 해결할 수 있게 도와준다.
- 이는
generator가GAN에서 흔하게 나올 수 있는 문제인 모든 샘플을 한 지점으로 붕괴시키는 것을 방지하게 된다.
- 그러나
모든 layer에batch normalization을 적용시키는 것은모델의 불안정성을 보여주었다. 따라서generator의 output과discriminator의 input에 적용하지 않는 방법을 선택하여 해당 문제를 해결하였다.
- 마지막으로
ReLU함수는generator에서 사용이 되지만output layer에서는Tanh가 사용이 된다. 본 논문에서는 유한한 범위를 갖는 활성화 함수를 사용하면 빨리 학습이되고, 훈련 분포의 color 공간을 cover할 수 있음을 관찰하였다고 한다.
- 그래서 본 논문은
discriminative에서Leaky ReLU를 사용했다. 이는 고해상도 작업에 더욱 수월하다고 알려져있다.
GAN논문에서는Maxout을 사용하였다.
- 해당 챕터의 마지막에서
DCGAN에서사용된 구조를 정리를 해주고 있다.
Discriminator는pooling layer를strided convolutional로 교체를 하고generator는pooling layer를fractional-strided convolutional로 교체를 한다.- 용어는 어렵지만 쉽게 생각하여
down sampling과upsampling을 하는 것이다.
- 용어는 어렵지만 쉽게 생각하여
Generator와Discriminator둘 다batchnorm을 사용한다.Fully Connected hiiden layer을 제거한다.FC 층을 제거하여Convolution layer로 대체하기 때문에 이미지의위치 정보를 더욱 잘represent할 수 있게 된다.
Generator에ReLU를 사용하고 output에는Tanh를 사용한다.Discriminative의 모든 층에는LeakyReLU를 사용한다.
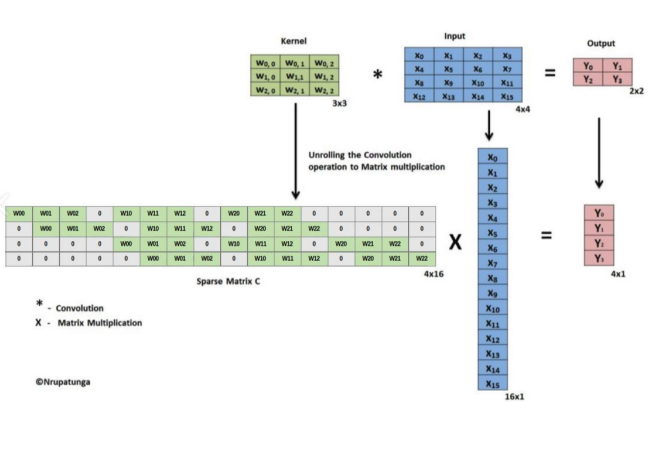
- 이때 나오는
Strided Convolutional이란kernel을 사용하여 연산을 수행하면서보폭도 같이 설정을 해주는 것이다. 따라서 위와 같은행렬 연산을 수행하여down-sampling을 할 수 있게 된다.
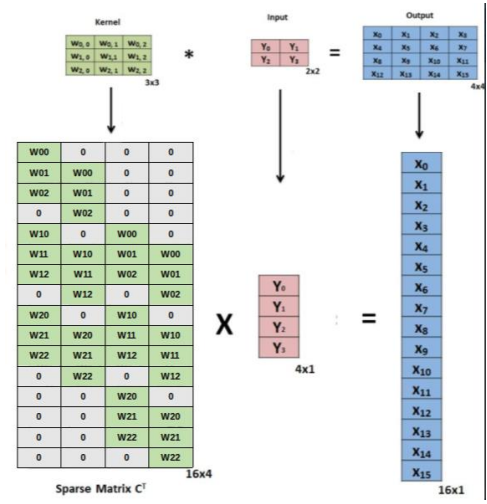
Fractional-Strided Convolutional은 input을transpose를 하여 계산하고 다시transpose를 하여 복원해주는 방식으로 동작하여up-sampling을 수행하게 된다.
Transpose convolution이라고도 불리운다.
Details of Adversarial Training
DCGAN을 학습하기 위하여본 논문에서설정한 기준들에 대해서 설명이 나온다.
- 이미지를 학습할 때 어떤
pre-processing을 하지 않았다고 한다.
- 모델이 데이터를
기억할 수 있기 때문이다.
Mini-batch stochastic gradient descent(SGD)(Mini-batch: 128)를 사용하여 학습을 하였다.
- 또한 기울기 0.2인
LeakyReLU를 사용했고Adam optimizer를 사용한다.
- 또
generator가input example을memorizing하는 것을 방지하기 위해Deduplication이라는 방법을 사용한다.
Deduplication은Autoencoder를 이용하여 학습에 사용할 이미지들을 이진화된code로 변환한 후해시 충돌이 일어나는sample들을 제거하여 275,000개의 샘플들을 제거 했다고 한다.
Empirical Valication of DCGANs Capabilities
Unsupervised learning의 평가하는 방법은 그것을supervised data에feature extractor로 추출하여 평가하는 방법이 있다.
- 따라서
DCGAN또한 represent를 잘 학습했는지 평가하기 위하여CIFAR-10데이터를 이용하여 실험을 수행하였고,discriminator로부터4x4 grid feature를 뽑아낸 다음,28,672크기의 벡터로 전환하여L2-SVM 모형을 훈련시켰다.
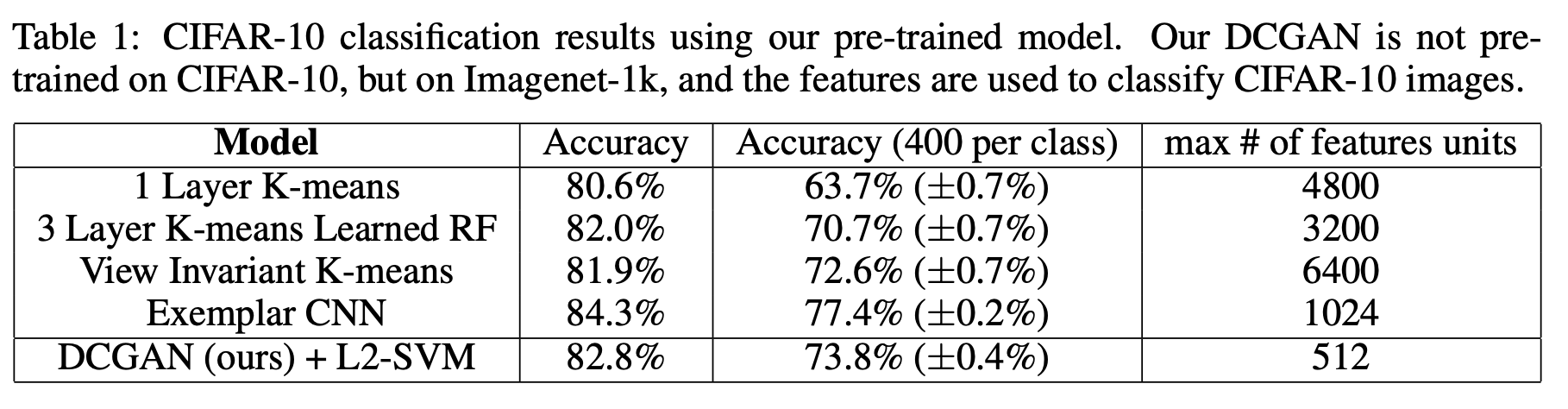
CIFAR-10의 실험 결과는위 그림과 같고exemplar CNN다음으로 성능이 제일 좋다.
Discriminator를 미세 조정하여 성능 향상을 기대할 수 있지만 그것은 future work로 남겨두었다고 한다.- 또한
CIFAR-10으로 학습되지 않아서learned feature에 대해domain robustness하다고도 할 수 있다.
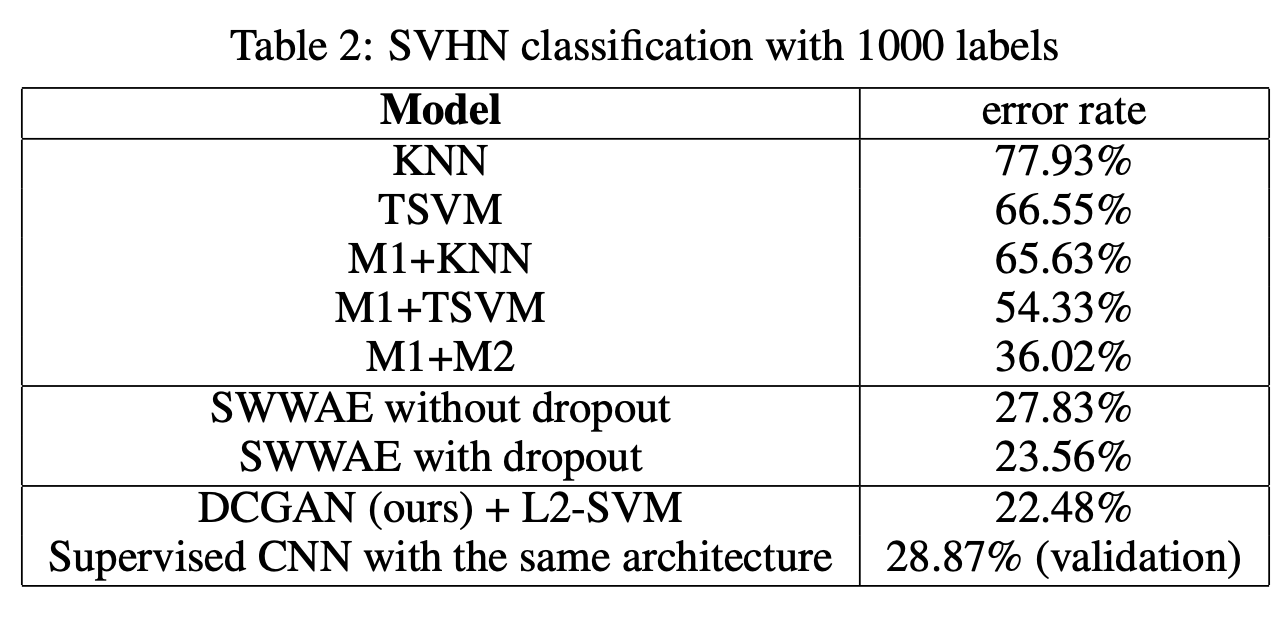
- 또한
StreetView House Numbers(SVHN)으로 같은 방법으로 성능을 내었을 때위 그림처럼SOTA를 달성하여Supervised CNN보다 더 준수한 성능을 보여서 본 논문에서는DCGAN에서의main key가 그저 CNN 아키텍처라고만 할 수는 없다고 알려준다.
WALKING IN THE LATENT SPACE
- 본 논문은
DCGAN을 이용한 여러 실험을 보여준다.첫 번째 실험으로Walking in the latent space이다. 이 실험은 정말generator가 학습 데이터를memorize를 하지 않았다는 것을 보여준 실험이다.
Latent Space z를 조금씩 움직여도memorize된 네트워크라면 조금의 움직임도 큰 변화를 나타낼 것이다.
- 왜냐하면
memorize되었다면 네트워크가 과적합이 되었을 가능성이 큰데, 이 경우latent space에서특정 data point에만 잘 대응이 되기 때문에 그것을 움직이면 일반화가 안되는 결과를 도출하게 될 것이다.
- 따라서
interpolation을 사용하여z1과 z2 사이의 값을 예측하여조금의 움직임을 만들고 그것을generate하여 결과를 확인하는 방법의 실험을 진행하였다.

위 그림은 9개의random data point들에 대하여interpolation을 수행한 실험의 결과인데 급격한 변화가 아니라 점차 변화하는 것을 관찰 할 수 있게 되므로, 이는 네트워크가memorized된 것이 아니라는 것을 증명하게 된다.
VISUALIZING THE DISCRIMINATOR FEATURES
두 번째 실험으로는Discriminator가 이미지의 구체적인feature를 잘 탐지하는지 확인하기 위하여 수행한 결과이다.
- 이미지의 구조 (침대, 거울 등)을 잘 탐지하는지에 대해 관심이 있어서 수행하는 실험이다.
- 실험을 수행하기 위하여
학습된 filter와random하게 초기화한 filter2개를 놓고 비교하는 실험을 진행하였다.

위 그림을 보면왼쪽(random filter)은 어떤 특징을 추출하기에 애매모호 한 반면,오른쪽(trained filter)은 침대의 특징 등을 잘 추출한 것을 확인할 수 있다.
Feature map이 어떤 특징을 뽑아서 결과가 나오는지 명확하게 알 수 없지만, 시각화 결과 잘 추출 한다는 것을 알 수 있게 된다.Generator가 아닌Discriminator인 이유는discriminator가 generator가 만든 이미지를 실제와 가짜인지 구별해야 하기 때문에세밀한 특징을 구분하는 능력이 있어야 한다.
FORGETTING TO DRAW CERTAIN OBJECTS
세 번째 실험으로는generator가 배우는representation은 무엇인가?의 실험이다.Generator가 생성한 것을 보면주요 장면의 구성 요소를 학습했다고 알 수 있는데 이것을직접 visualization으로 확인하는 실험이다.
Generator의 네트워크를 학습시킬 때특정 객체를 나타내는 filter를 제거하면 결과가 그 객체가 제거된 상태로 나오는지에 대한 실험을 하였다.
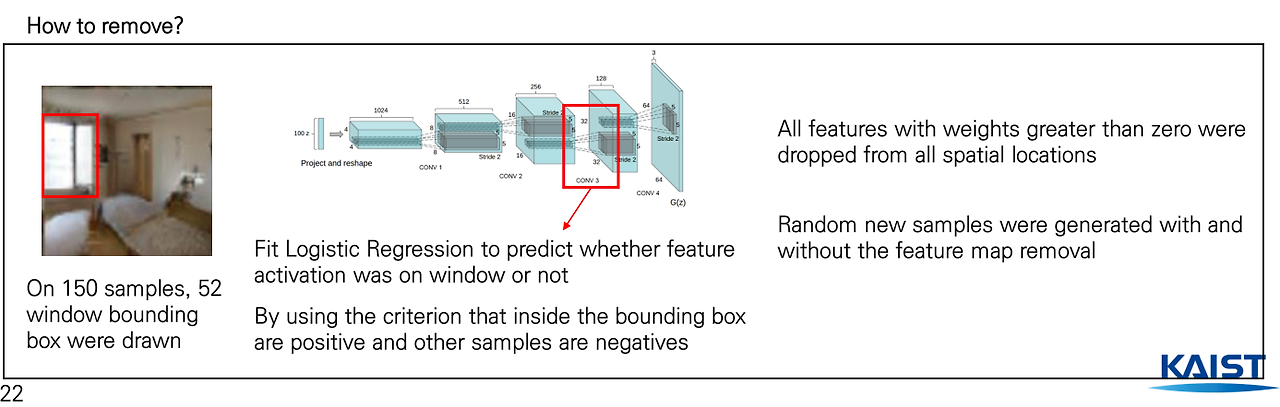
- 실험을 진행하기 위하여
위 왼쪽의 그림처럼제거할 창문(객체)에bounding box를 그린다. 그 다음으로 Generator의 두번째 끝단의 네트워크에서Logistic Regression을 훈련시켜서 bounding box 내부는 양수고 바깥은 음수가 나오는 경우, 즉 다른 말로 해당 부분에 대해서가중치가 양수 값(bounding box 내부)을 갖는 모든 경우는 drop을 시킴으로써 제거를 한다.
- 그렇게
제거된 filter를 사용하여generate을 수행했을 때 창문이 없는 사진이 나오는지를 확인을 해보았더니 아래와 같은 결과가 나오게 되었다.
위 그림을 보면맨 위는 filter에 drop하기 전을 나타내고그 아래는drop한 결과를 나타낸다. 그림 중 빨간색을 보면 기존 창문이나 문이 벽이나 문으로 대체가 된 것을 확인 할 수 있게 된다.
- 따라서
위 실험을 통하여generator가특정 object를 보고 generate 한다는 것을 알 수 있게 된다.
VECTOR ARITHMETIC ON FACE SAMPLES

네 번째 실험으로는vector의 산술 연산을 통하여 의미상으로 유사한 다른 샘플들을 형성할 수 있는 지를 실험해본 것이다.
위 그림은 해당 실험의 결과인데웃는 여성에서무표정의 여성을 빼고무표정 남자를 넣으면웃는 남자가 된다는 것을 확인할 수 있다.
- 실험을 할 때
하나의 sample가지고는z vector로 표현할 수 없어서 적어도 3개의sample의 평균으로 일관되고 안정적인generation을 보여준다고 한다.
- 이 실험을 통하여
비지도 학습 모델에서하나의 z space가객체의 속성들을 학습했다는 것을 알 수 있게 된다.
본 논문에서는이러한 점으로 아주 많은 것들을 할 수 있을 것이라고 표현한다.- 아래의 실험은 이런 객체의 속성을 학습했다는 것을 보여주는 실험이 나오게 된다.
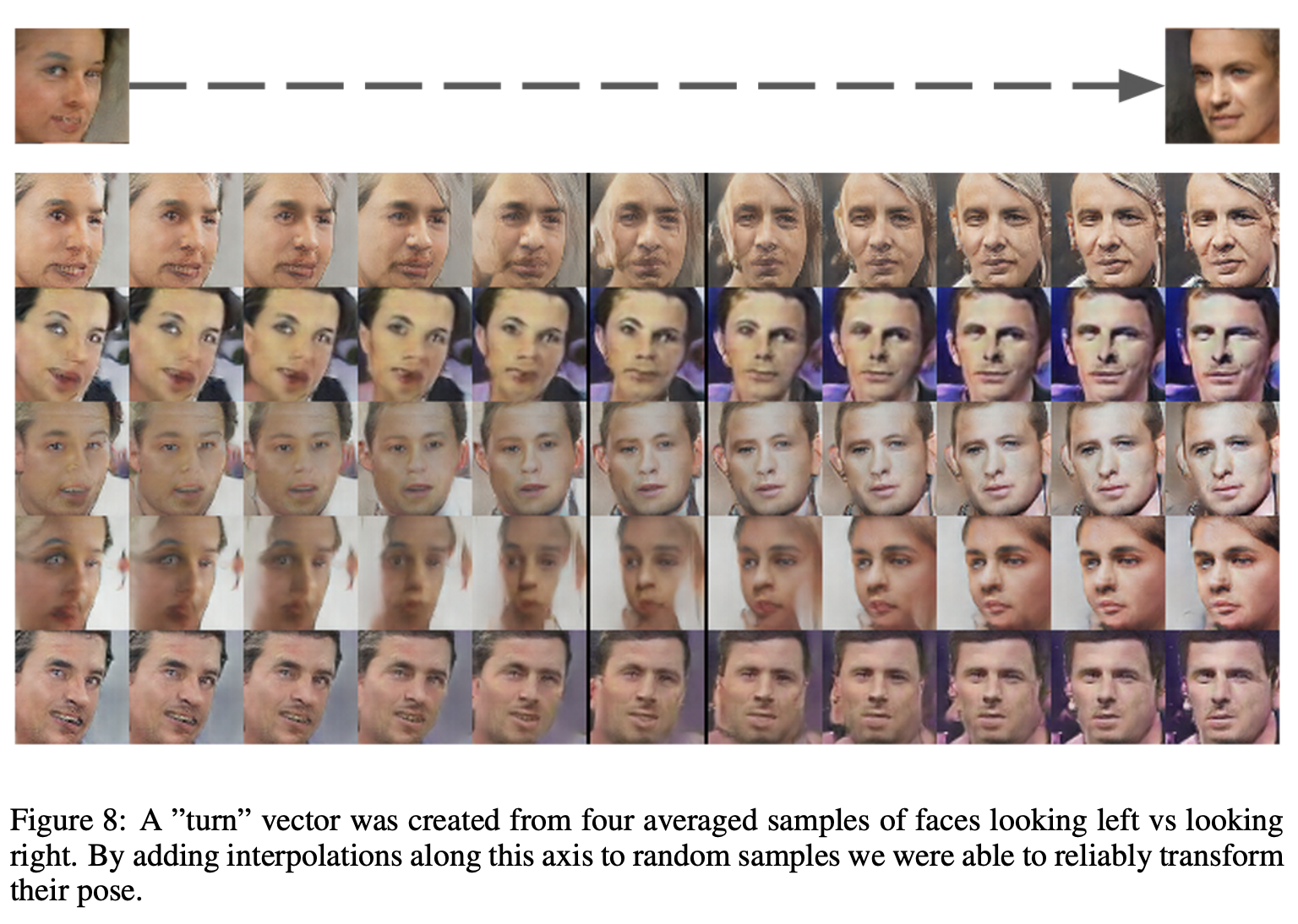
위 그림은왼쪽을 보고 있는 얼굴을 만들어내는 input $z_\text{left}$들의 평균 vector $\bar{z_\text{left}}$과오른쪽을 보고 있는 얼굴에 대응하는 $z_\text{right}$들의 평균 vector $\bar{z_\text{right}}$를 계산한다.
$$z_{\text{interp}} = (1 - \alpha) \cdot \bar{z_{\text{left}}} + \alpha \cdot \bar{z}_{\text{right}}$$
- 이
두 벡터의 사이를 잇는축(axis)을interpolating하여Generator에 넣어보았더니 천천히 “회전(turn)“하는 얼굴들이 나오는 것을 볼 수 있다.
Generator에 들어가는 것은 $\alpha$값을 조절한 $z_{\text{interp}}$이다.
- 이를 통해
generator가 단순히 이미지를 무작위로 생성하는 것이 아니라latent vector의 변화에 따라이미지의 특정 속성(얼굴의 방향 등)을 조절할 수 있는 능력을 가지고 있다는 것을 알 수 있게 된다.
Generator는latent vector의 특성에 따라 이미지의 방향도 자동으로 점진적으로 조절하여, 왼쪽에서 오른쪽으로 회전하는 얼굴을 만들게 되는 것이다.