[CS231n] 10. Recurrent Neural Networks
Contents
개요
CS231n의 10강에 대한 내용을 정리 할 것이다.
Recurrent Neural Networks
- 이번 강의에서는
Recurrent Neural Networks에 대해서 설명을 한다.
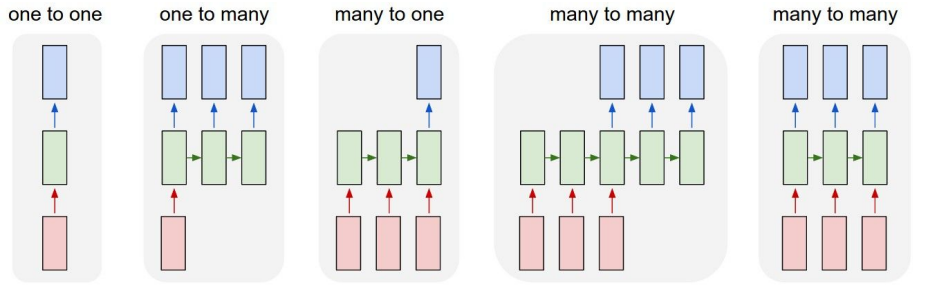
- 지금까지의 networks는
one-to-one의 구조를 띈 모델이지만 위 그림과 같이 여러 구조를 띌 수 있게 된다.
- 따라서 각 구조 별로 다양한
task로활용할 수 있다.
one-to-many- image captioning
many-to-one- sentiment classification
many-to-many- machine translation
- videio classification on frame level
$$h_t = f_W(h_\text{t-1},x_t)$$
- 다음은
RNN의 기본 수식이다. 이전 상태($h_\text{t-1}$, hidden state)와 입력 값($x_t$)을 계산하여new state로 나오게 된다.
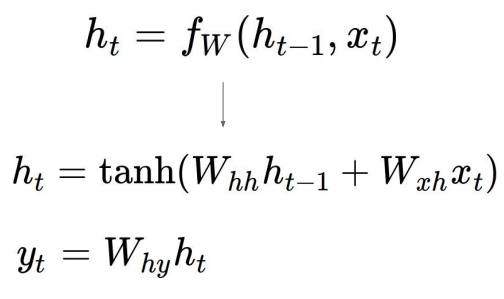
- 더 자세한 수식은
위 그림과 같다.
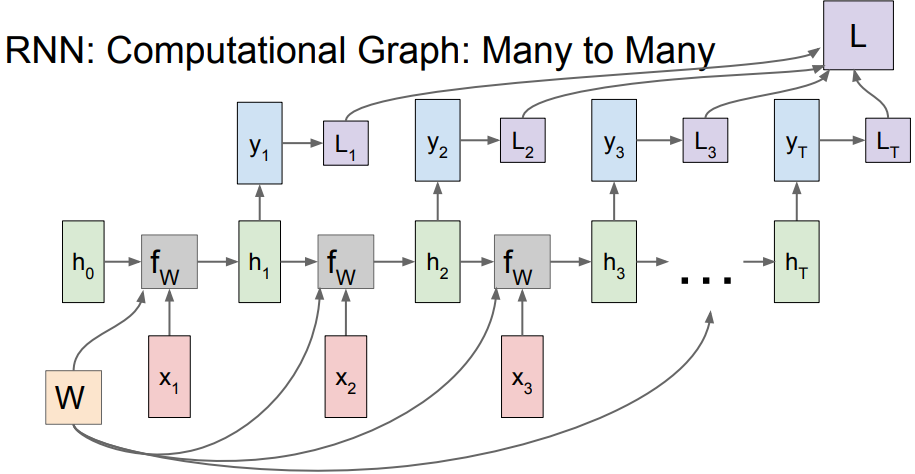
- 위의 수식을 기반으로
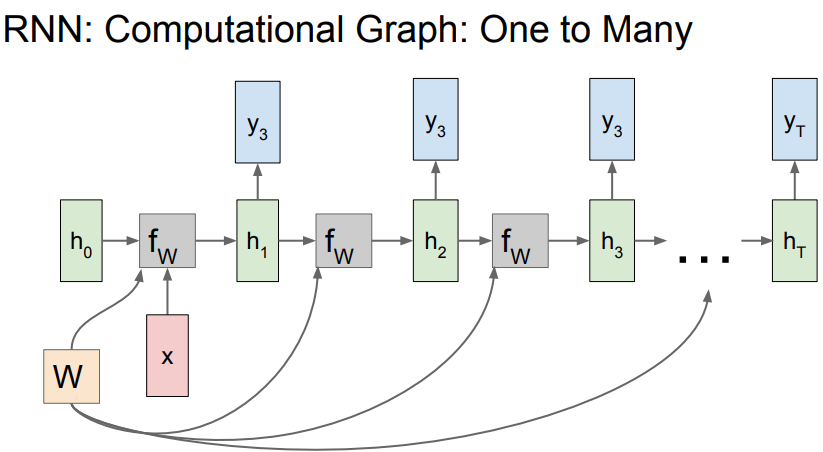
RNN의Computational Graph로 표현을 하게 된다면위 그림과 같다.
- 보면
각 스텝에서 다 같은W를 사용하는 것을 확인할 수 있게 된다.
위 그림은RNN에서Many-to-Many일 때Loss계산 까지 표현되는 그림인데 각각의 time-step마다local gradient를 계산하게 되고 그것이 합쳐진L까지 가서upstream gradient로 내려오게 된다.
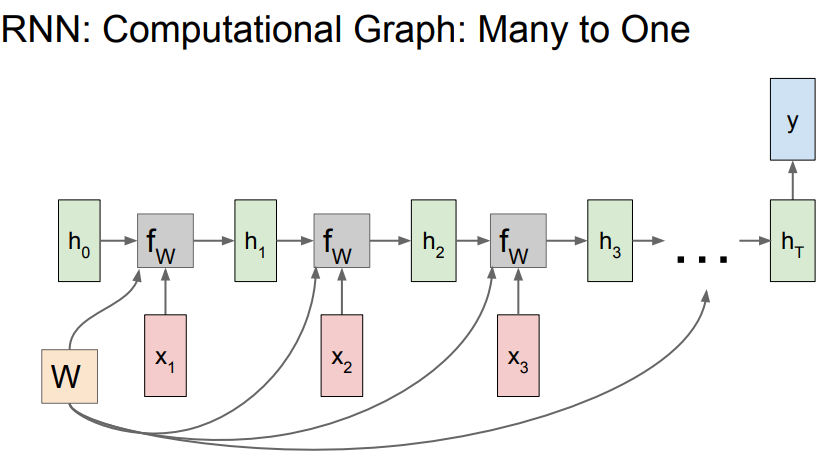
- 다음은
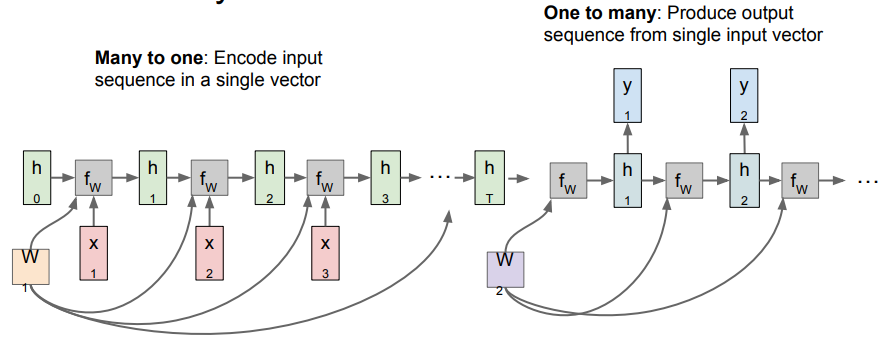
Many-to-One일 때 인데 최종 output인 y가summarize context를 모든time-step에 따른 하나의 결과를 담고 있다.
- 다음은
One-to-Many인데 이것은fix size형태로 입력이 되고variable size인output을 출력하는 형태이다.
- 이러한
Many-to-One구조와One-to-Many를 섞은 구조인Seq2Seq구조도 있다.
Encoder에서 다양한 크기의 input이 들어오고 그것의 전체를 요약하는 $h_t$가 있게 된다.
Encoder에서 나온 vector를Decoder로 넘겨 다양하게 출력을 할 수 있게 한다.
- 이때 입력, 출력의 크기를 조절하기 위하여
입력 토큰,출력 토큰을 지정하여 모델이 처음과 끝을 알 수 있게 한다. - 이 구조는 번역을 하는 task에서 사용할 수 있게 된다. (영어 -> franch)
- 이제는 하나의 문자를 입력 받고 다음으로 올 문자를 예측하는 모델을 설명할 것이다.
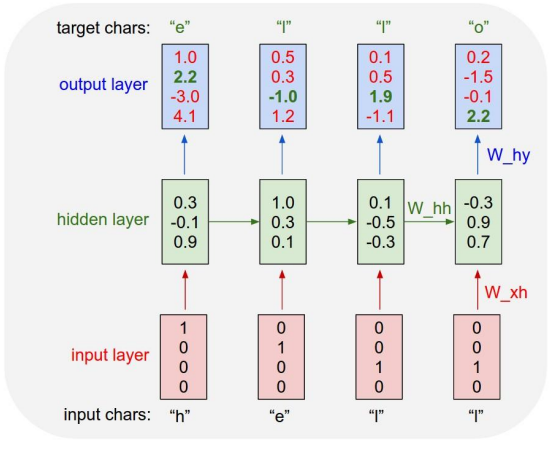
- 문자를 모델에 입력하기 위하여 하나의 벡터로 넣기 위하여
embedding작업을 거치는데embedding방법 중one-hot-encoding의 방법을 사용하였다.
- 그 후 그것에 가중치 행렬($W_\text{xh}$)을 곱하여
hidden layer로 들어가고 또 그게 다시output layer로 출력이 된다.
- 여기서
hello라는 결과를 보여야 하기 때문에 맨 처음에e라는 출력값을 가진다. 하지만 이 경우 잘못 예측을 하여o로 예측을 한 경우이다.
- 다음으로
e가 input으로 들어가고 새로운hidden state를 만든다. 이러한 과정을 계속 거치면 이 모델은 이전의 문장들의 문맥을 참고하여 다음 문자가 무엇일지 예측을 할 수 있게 되는 것이다.
- 그렇다면 이 모델의
Test time에서는 어떻게 작동을 하고 있는지 보여준다. 이 모델을 잘 활용을 하기 위해서는sampling이라는 샘플링 기법을 활용하는 것이다.
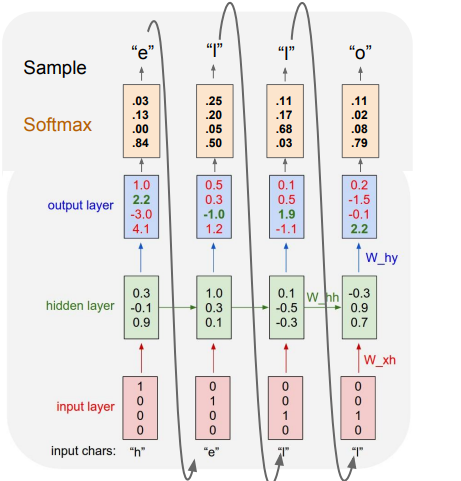
위 그림은 모델이output layer를 거쳐softmax를 취하여 확률 분포를 사용하여 sampling을 한 과정을 나타낸다.
- 해당 경우에 e는 뽑힐 확률이 굉장히 작았음에도 불구하고 운이 좋게 e가 샘플링 되었다.
- 또한 이 샘플링으로 나온 e를 다음 input으로 넣어주고 반복 과정을 거쳐
test를 하게 된다.
- 가장 높은 스코어를 선택하지 않고 샘플링을 하는 이유는 모델에서 다양성을 얻을 수 있게되기 때문이다.
- 항상 h를 첫 input으로 놓는다고 할 때, 확률분포로 샘플링을 하게 된다면 그럴듯한 다양한 문장들을 출력할 수 있어 이것이 출력의 다양성으로 이어진다.
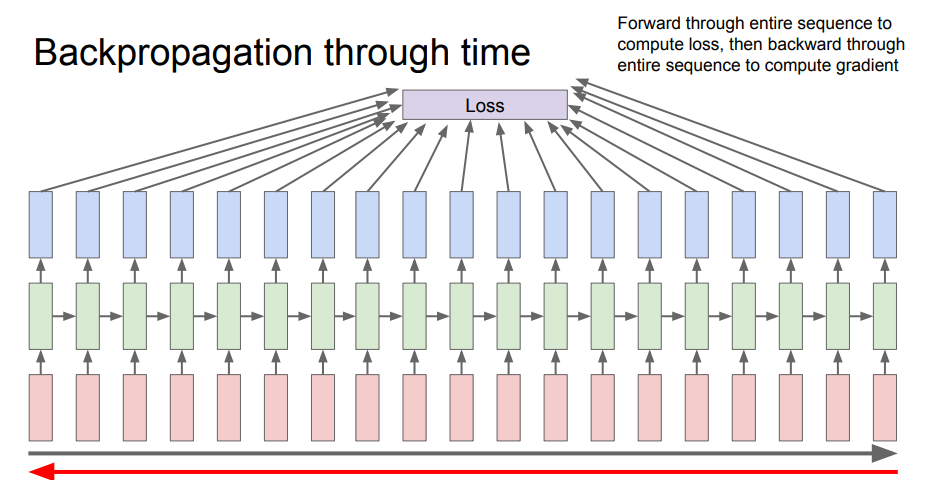
- 다음은
RNN에서 역전파를 사용했을 때를 나타낸다. 각 스텝마다의loss를 계산해서 최종적인output을 나타내게 되는데 시퀀스가 너무 길게 되면 문제가 생길수도 있다고 한다.
- 길면 메모리 사용량도 많고 학습이 너무 느릴 것이다.
- data point의 모든 요소에 대한 기울기를 계산하는 것은 엄청난 비용을 초래한다.
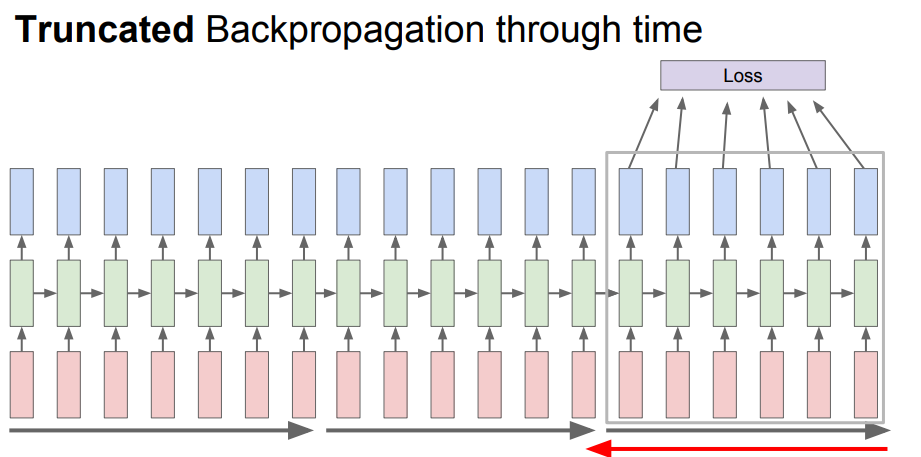
- 따라서 이러한 문제를 해결하기 위하여 나온 방법은
truncated backpropagation이다.
- 입력이 너무 길다고 하더라도 train할 때 한 스텝을 일정 단위로 자르고 단계를 진행하기 때문에
위의 문제를 해결할 수 있다.
- 이전에 계산한
hidden state는 계속 유지하고 반복해야 한다. backpropagation은 현재 배치만큼만 진행해야 한다.
Image Captioning
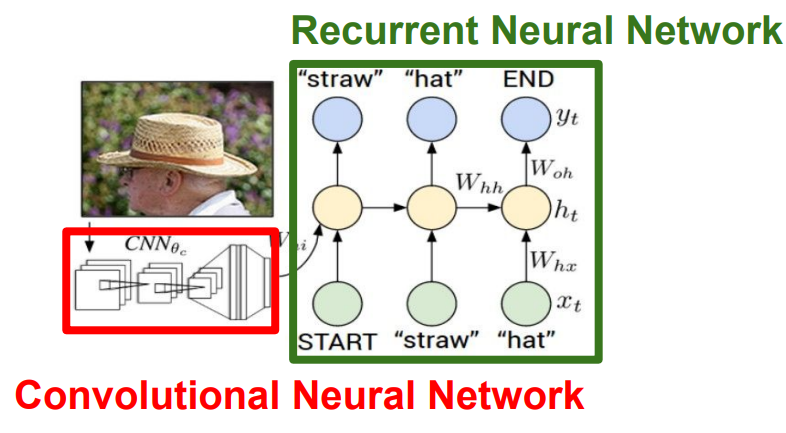
- 다음은
Image captioning에 관한 설명이다.Image captioning을 하기 위해선CNN에Image를 넣고 CNN의result vector를 다시RNN에 넣어서caption에 사용 될 문자를 하나씩 생성해가는 방식이다.
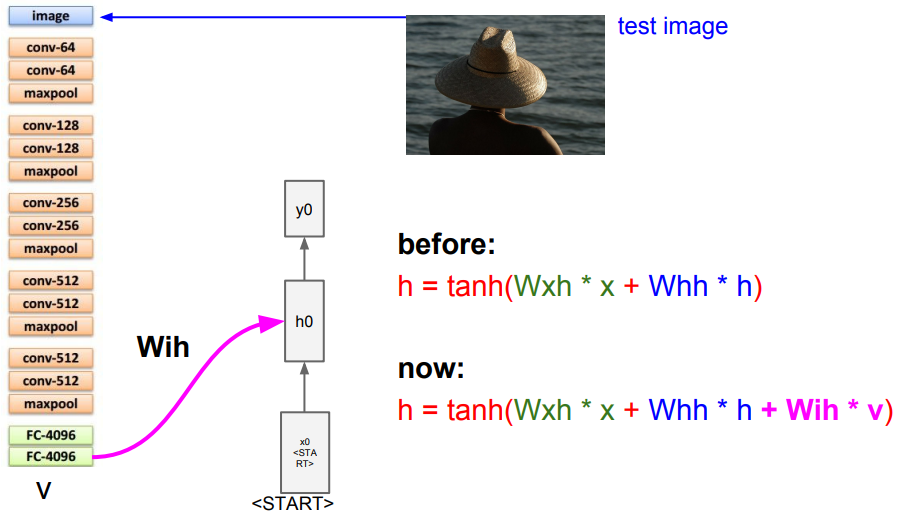
위 그림을 보면 CNN에서 마지막 출력(softmax) 전에 값들을 RNN의 모델의input으로<start> 토큰과 함께 넣고 이미지 정보를 추가하기 위하여 세번째 가중치 행렬을 추가한다.
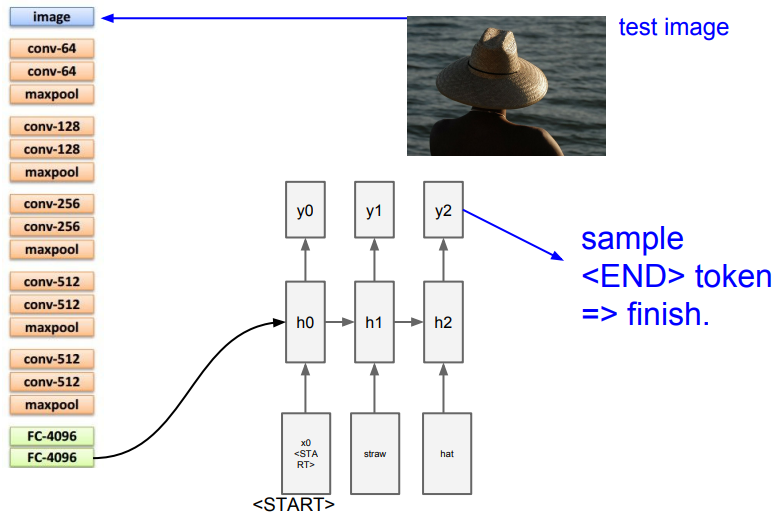
- 그 후
sampling을 통하여 output을 뽑고 그 단어를 다시 다음 스텝의 입력으로 넣는 과정을<END> 토큰이 나올 때 까지 반복하게 된다.
Image captioning은supervised learning이기 때문에label이 있어야 한다.
Image Captioning with Attention
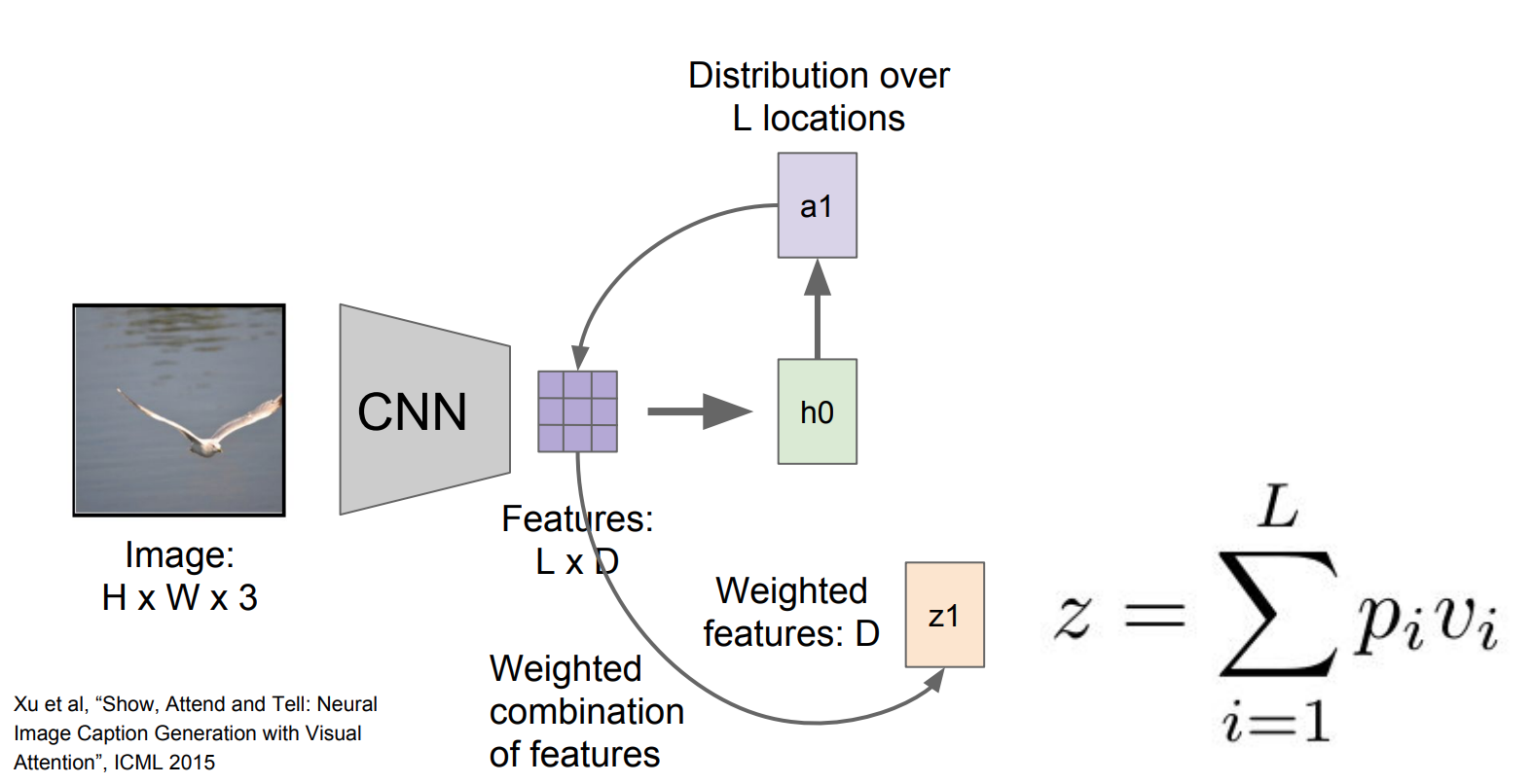
Image captioning을attetion mechanism과 함께 사용하는 예시를 설명할 것이다.
- Image를
CNN으로 먼저Feature map vector를 뽑고 이 벡터는 각각의 벡터가 공간 정보를 가지고 있는 것이다.
- 이 벡터를 사용해서
RNN을 활용을 하는데 $h_\text{0}$은 이미지의 위치에 대한 분포를 계산하고, 그것의 결과인 $a_\text{0}$이 다시feature map과 계산을 하여 이미지에서 살펴보고자 하는 위치에 대한 분포를 나타내는 $z_1$ 도 함께 생성하게 된다.
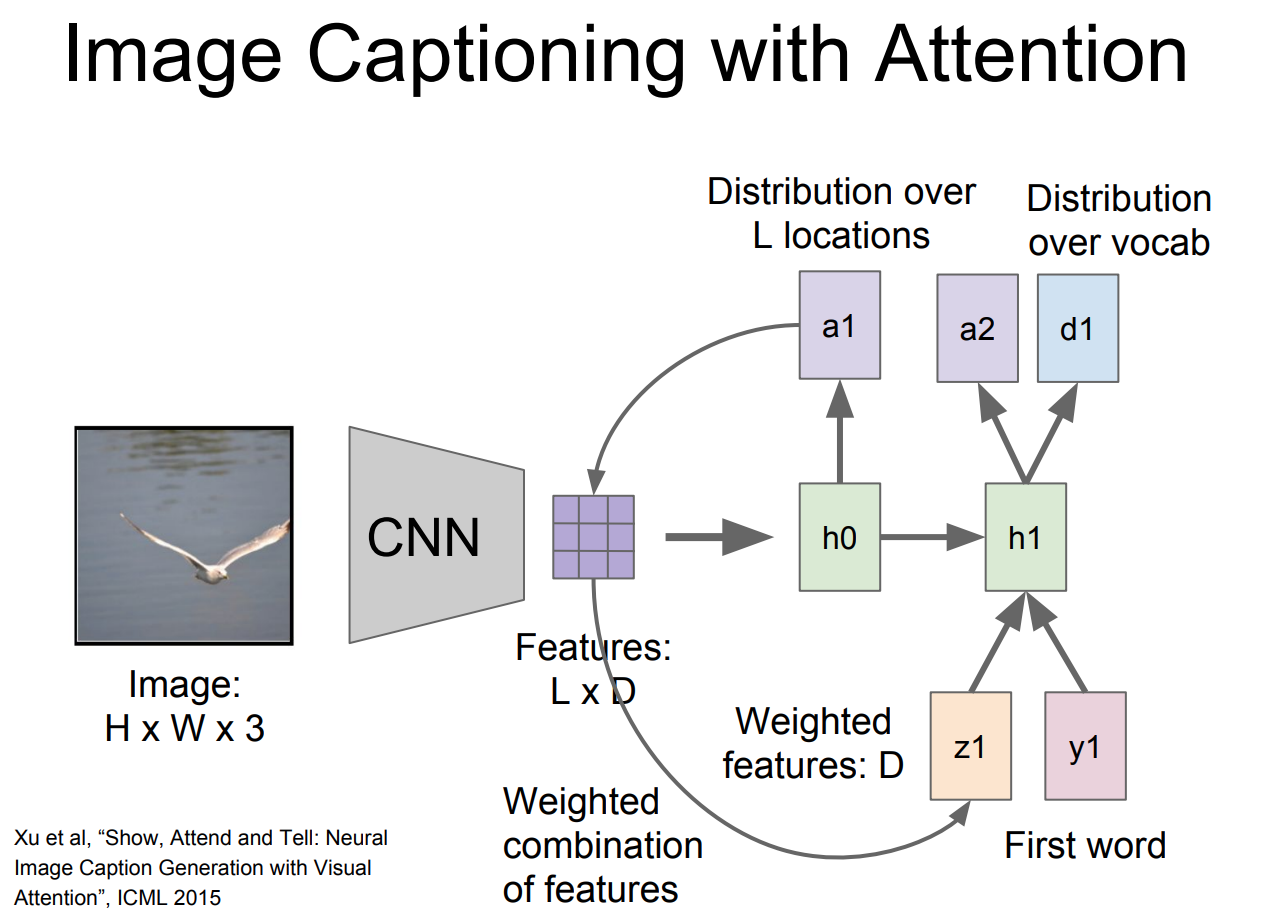
- 이때 계산된 $z_1$은 다음 번 단계일 때 input으로 들어가고 그 후
위 그림과 같이 두개의 출력으로 나타내게 된다.
- 이것이 계속 끝날 때 까지 반복이 된다.

- 따라서 위 그림은 모델이
caption을 만들기 위하여attention하는 것을 시각화 하는 그림이다.
- 따라서 모델이 caption을 만들기 위하여 실제로 의미 있는 부분을 집중하고 있는 것을 확인 할 수 있게 된다.
- 이러한 방법으로
Visual Question Answering Task도 가능하다.
MultiLayer RNNs
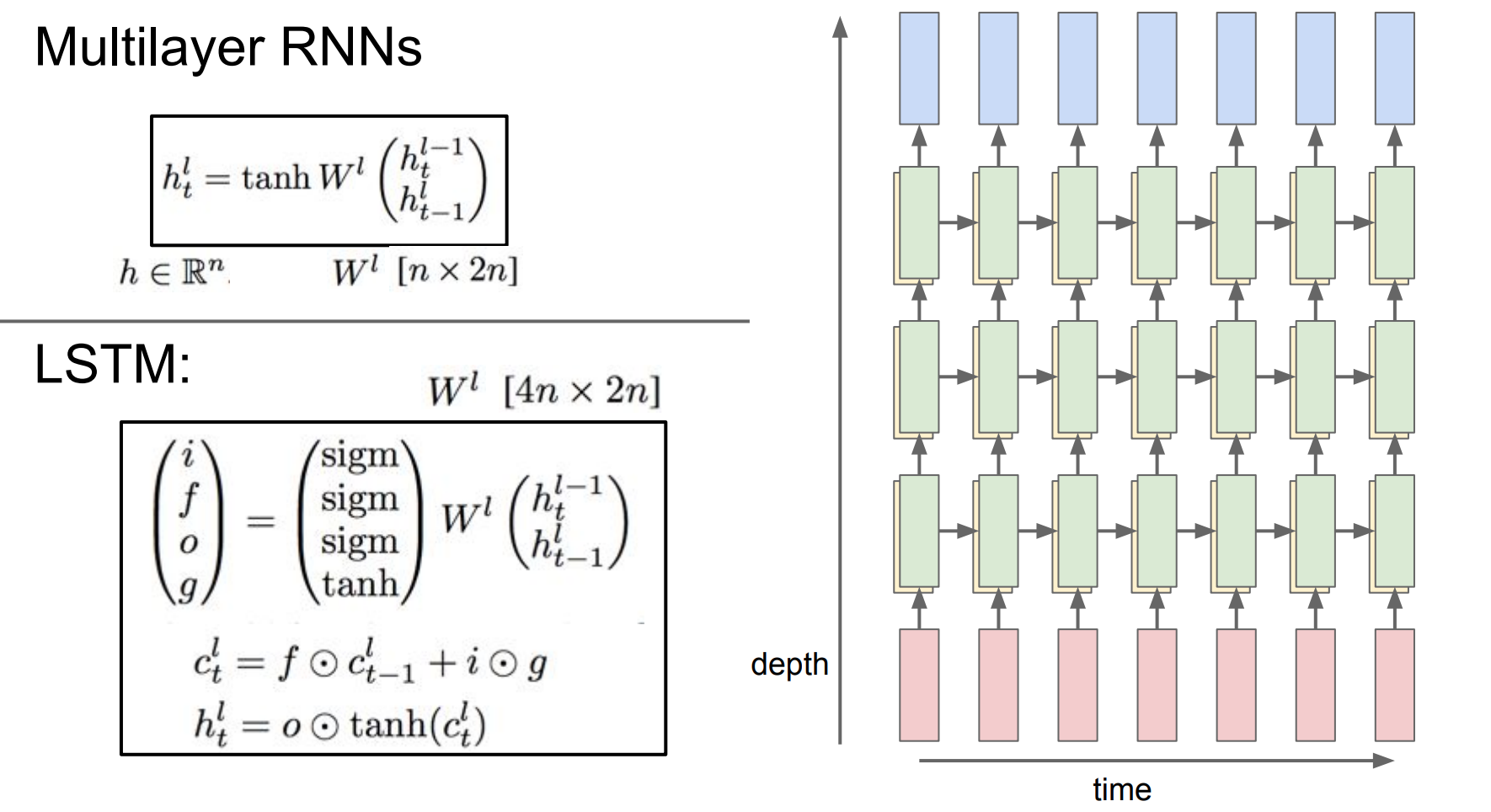
- 지금까지는
hidden state가 하나인 RNN을 배웠지만hidden state가 여러개인multilayer rnn도 가능하다는 슬라이드이다.
RNN을 한 번 돌리고hidden state가 생기고 이것이 바로다른 RNN cell의input으로 들어가는 것을 확인 할 수 있게 된다.
- 모델이 깊어질수록 성능이 더 좋아진다.
- 보통 layer를 2~3개를 쌓는다.
LSTM
- 이러한
RNN에도 문제점이 있다. 바로 RNN의gradient update과정에서 발생하는 문제점이다.
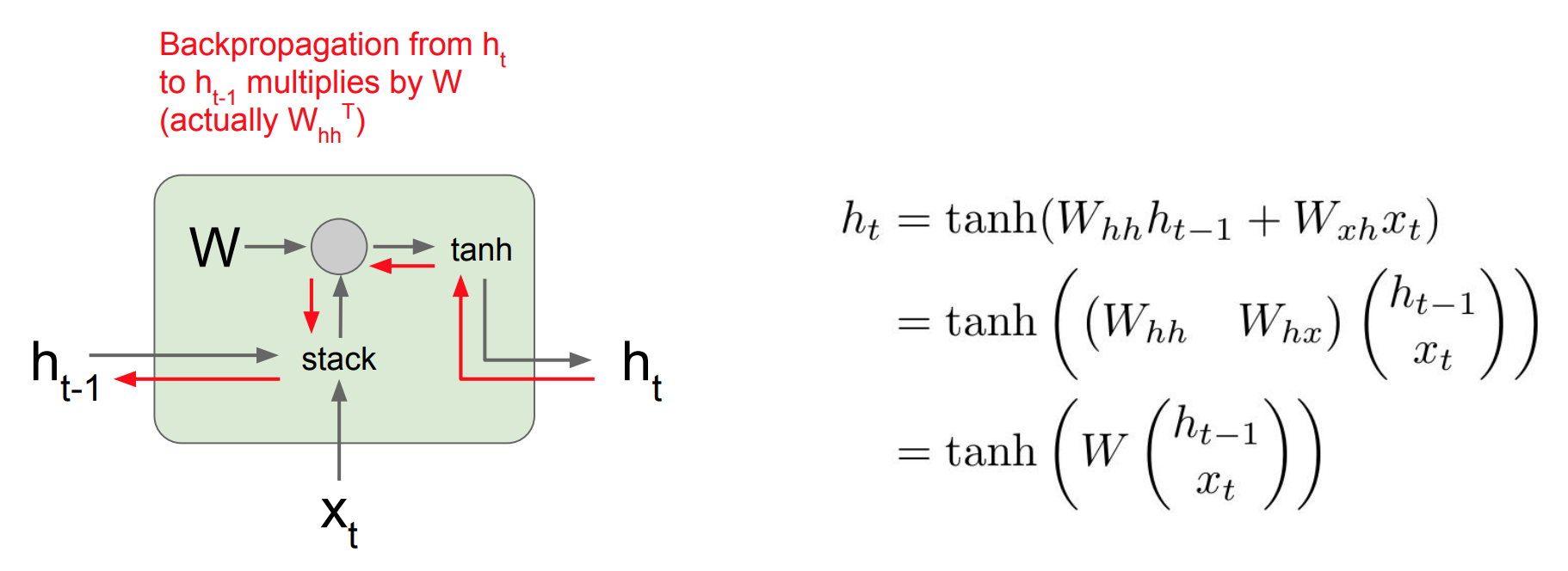
위 그림은RNN에서backward pass일 때의 모습이다. 이때 $h_t$에 대한 미분 값을 얻게 되고 loss에 대한 $h_\text{t-1}$의 미분값을 계산을 하게 된다.
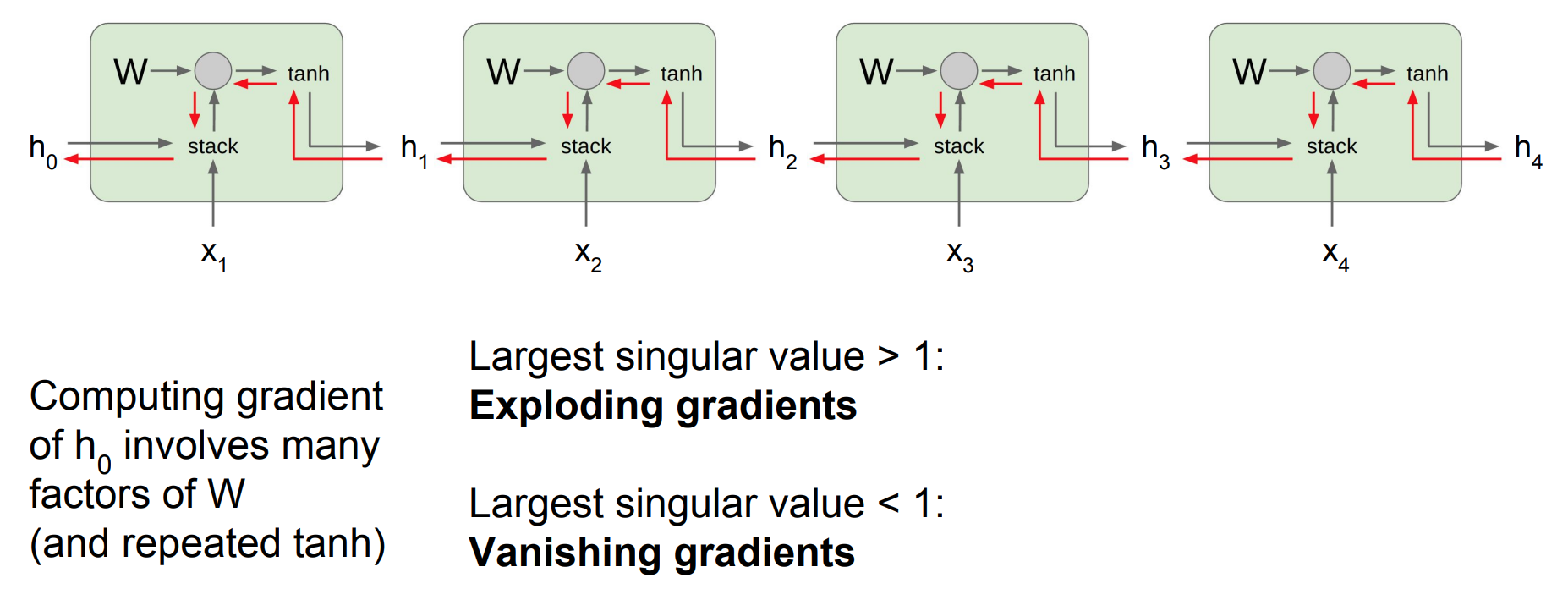
위 그림은 해당 과정을여러 셀일 때 나오게 되는 그림이다. 이때 보면 $h_0$의gradient를 구하려고 하면 각 셀의 같은 값을 가지는W가 개입하게 된다.
- 이 때 계속 곱해지는
W의 값을 1보다 크면 결국exploding될 것이고 1보다 작으면gradient가 사라지는vanishing gradient현상이 일어날 것이다.
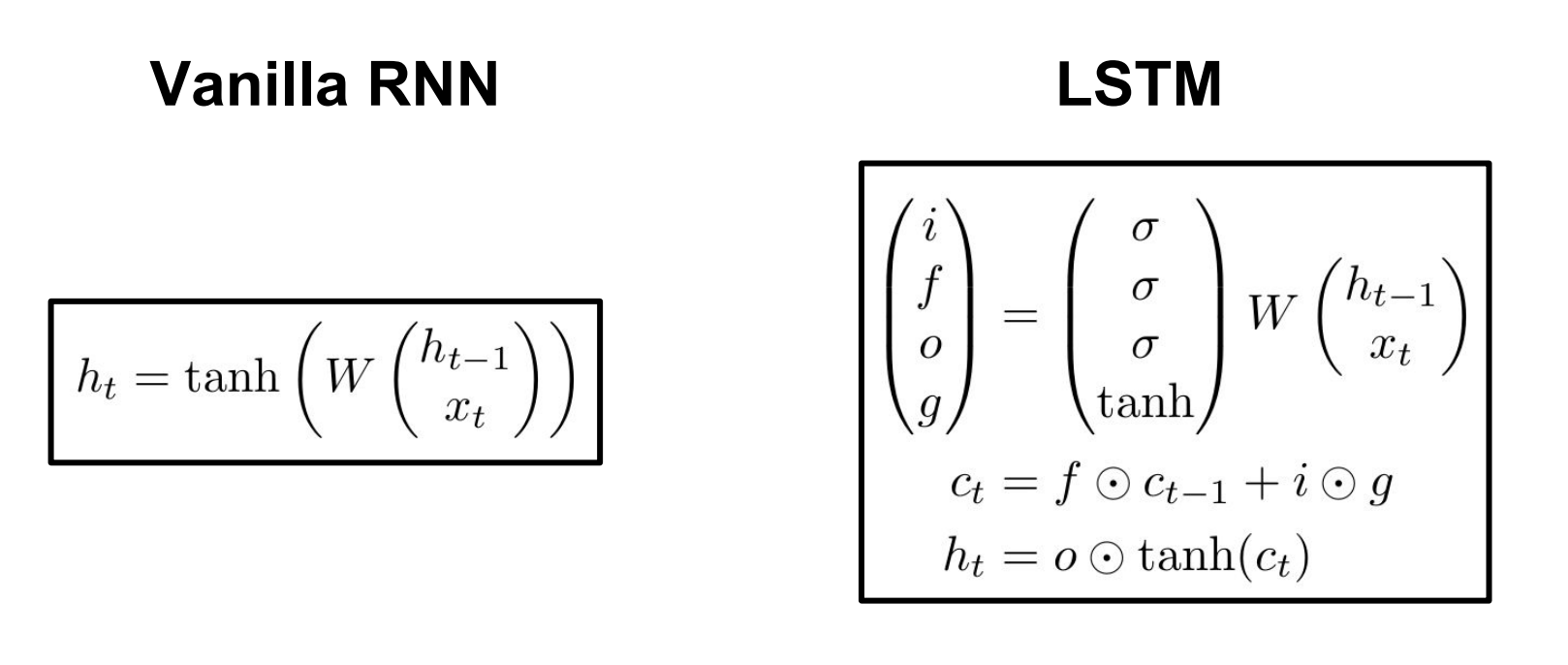
- 따라서 이러한 문제를 해결하기 위하여
LSTM이 나오게 되었다.LSTM은 한 셀에 두개의 hidden state를 가지고 있다. $c_t, h_t (cell state, hidden state)$
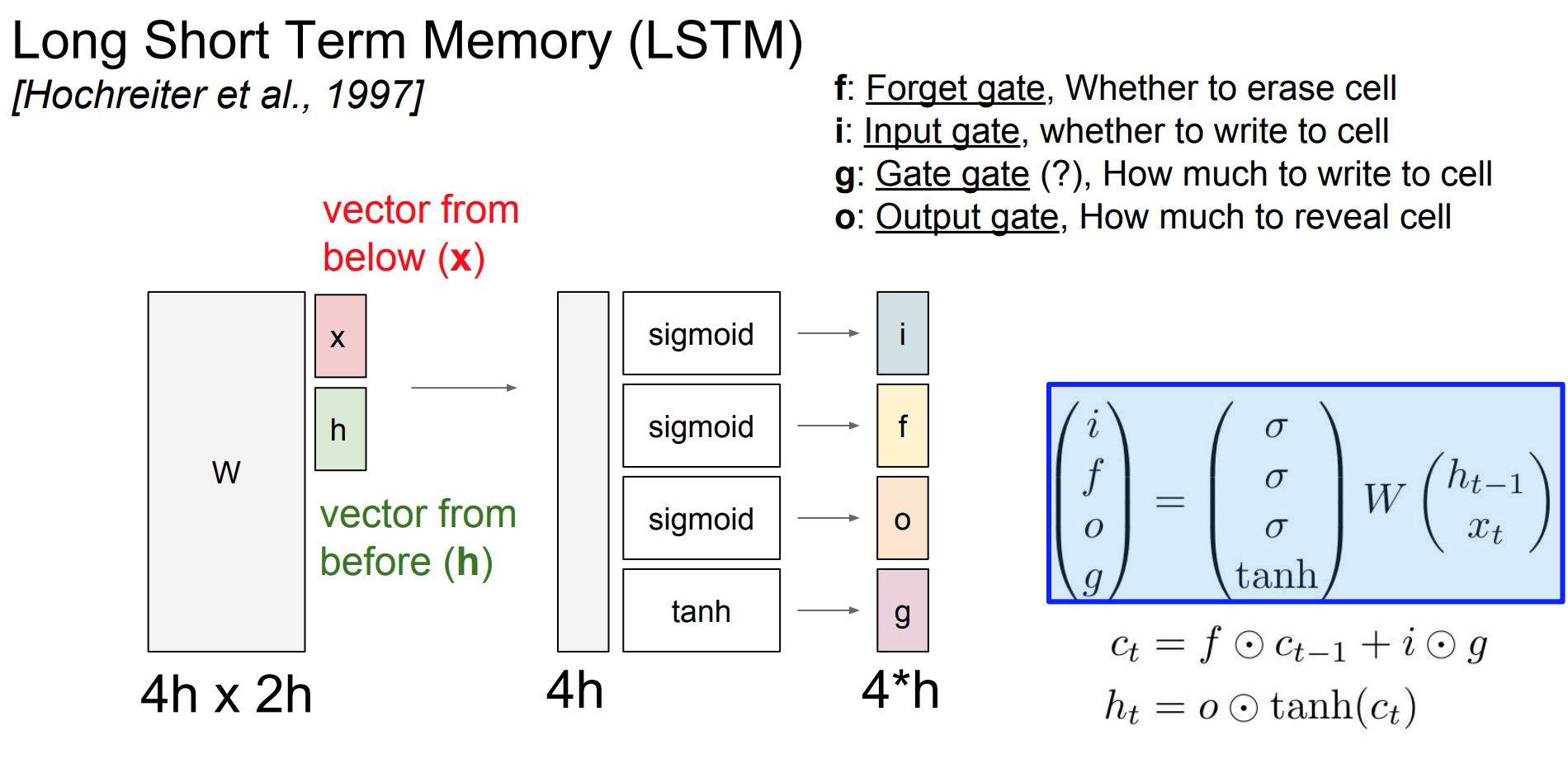
위 그림은 LSTM의 구조를 나타낸다.LSTM은 각각 다른 4개의weight 행렬에이전 상태에서 온x와h를 합쳐 행렬 곱을 하여 4개의 gate로 output을 내게 된다.
f gate는 이전 스텝의 cell 정보를 얼마나 지울지에 대한 망각 게이트 이고 이것이 가능한 이유는 sigmoid를 activation으로 하기 때문에 0,1사이의 값으로 조절 할 수 있게 된다.
i gate는 input gate이고 $x_t$에 대한 가중치이고g gate는 gate gate이고 input cell을 얼마나 포함시킬지 결정하는 가중치 행렬이다. 또한o gate는 output gate로 cell을 얼마나 드러낼 것인지에 대한 가중치 행렬이다.
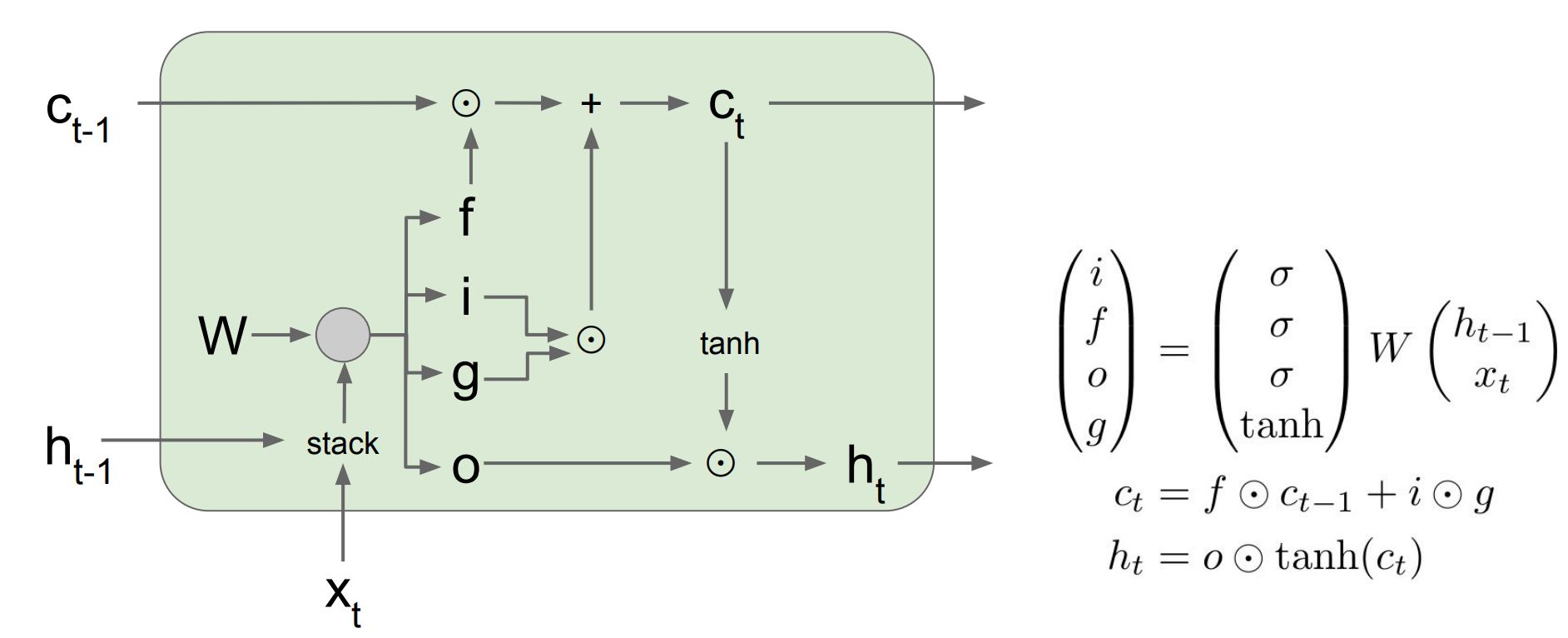
- 이런
LSTM cell구조를 더욱 명확히 나타내기 위한 그림이다. 이전cell state와hidden state를 입력으로 받고 $h_\text{t-1}$와 $x_t$를 stack하여 가중치 행렬과 계산하고 각각 $c_t$와 $h_t$를 계산 하는 것을 확인 할 수 있다.
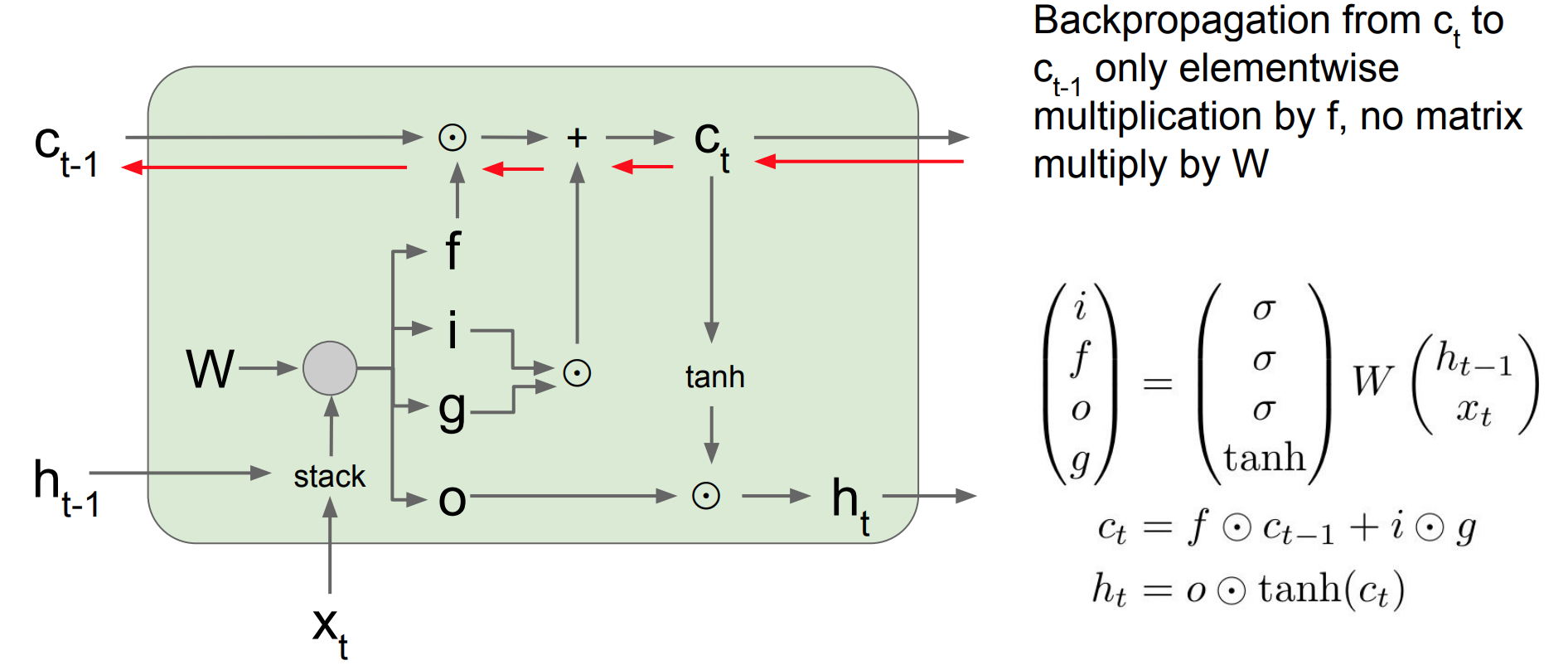
- 다음은
LSTM cell의 gradient과정을 나타낸 것이다.LSTM은 역전파를 수행할 때 $c_t$에 대한 역전파만 수행하여 forget gate에 upstream gradient가 곱해지는 것을 확인이 된다.
- 왜냐하면 $c_\text{t-1} * fgate$ 이므로
행렬 곱이므로gradient update 입장에서 봤을 때 $fgate$만 업데이트 시 사용이 된다.
- 따라서 같은
W의 값이 계속 곱해지는vanilla rnn과 달리 forget gate의 값이 스텝마다 달라지기 때문에 이러한 문제를 해결할 수 있게 되었다.
- 그렇다고
vanishing gradient의 문제가 완전히 해결된 것은 아니지만vanilla rnn보다는 심하지는 않다.- 매 스텝마다
f의 값이 달라지기 때문이다.
- 매 스텝마다
- forget gate의 sigmoid 값으로 bias를 1에 가깝게 만들어주면
vanishing gradient를 많이 약화시킬 수 있습니다. - W 값이 곱해지지 않아되기 때문에 마치 고속도로 처럼 gradient를 위한 빠른 처리